
이 페이지는 앤드류 응 교수님의 강의를 듣고, 개인적인 기록을 위해 정리한 내용입니다.
이 페이지는 실제 강의를 들으시고 정리용으로 참고하시는 것을 매우매우매우 권장드립니다.
[ 한글 자막 다 있음 ]
]1단계 뿐 아니라 2, 3, 4 단계 강의도 존재합니다!
앤드류 응 교수님의 강의가 임베드(유튜브) 되어 있으며, 부트코스에서 각 강의마다 정리한 내용도 존재합니다.


딥러닝 1단계 강의 정리
기본 개념 정리
•
딥러닝(Deep learning) : 신경망(NN)을 학습시키는 것을 칭한다.
•
신경망(NN) : Neural Network(NN)으로 부르며, 입력(x)와 출력(y)를 매칭해주는 함수를 찾는 과정이다.
신경망의 특징
•
머신러닝(machine learning) : 컴퓨터가 데이터 학습을 통한 경험으로 기능을 개선/발전하는 방법이다.
머신러닝 종류
학습에 필요한 데이터 종류
•
CNN : 합성곱 신경망으로 부른다.
CNN 특징
•
RNN : 순환 신경망으로 부른다.
RNN 특징
왜 최근에 딥러닝이 부상하였을까?
딥러닝이 발전할수록, 스스로 학습 → 개선 → 구현의 반복이 빨라지면서 기하급수적으로 발전하게 된다.
깊은 모델 일수록 더 많은 데이터가 필요하며, 이는 결과에 직접적인 영향을 준다.
최근에는 아래 3가지 이유로 딥러닝의 더 빠른 발전이 이루어졌다.
1.
수집되는 데이터가 매우 많아졌다. (인터넷 사용, 전자기기 사용 등)
2.
컴퓨터 성능 향상 (더 향상된 모델을 만들기 위한 하드웨어의 발전)
3.
알고리즘의 개선 (이전에 적용하지 못한 새로운 알고리즘으로, 많은 문제 해결)
이진 분류
이진 분류의 목표는 입력 값으로 생성된 특성 벡터 로 → 분류한 결과() 가 0(거짓) 또는 1(참)로 구분하도록 학습시키는것이다.
강의에서의 기호 표기법
예시로 64px * 64px 고양이 사진이 하나 있을 때, 해당 사진이 고양이 사진인지 구분하는 훈련을 한다.
이때 각 픽셀은 RGB 값을 각각 가지고 있으며, 그렇다면 사진의 정보를 아래와 같이 표현할 수 있다.
•
Red (64 * 64 행렬)
•
Green (64 * 64 행렬)
•
Blue (64 * 64 행렬)
이때, 모든 픽셀들의 정보를 하나의 벡터에 펼치기 위해 하나의 열에 담은 특성 벡터 를 다음과 같이 설정한다.
이 특성 벡터 차원을 이나 간략하게 으로 표현한다.
•
Red 픽셀 강도 정보 + Green 픽셀 강도 정보 + Blue 픽셀 강도 정보를 한 열에 설정한 특성 벡터
이때 전체 차원은 64 * 64 * 3 = 12288이 된다.
이 와 결과 를 하나의 훈련 샘플 로 묶으며, 와 같이 번째 훈련 샘플인것으로도 표현한다.
전체 훈련 샘플은 로 표현한다.
이때 전체 훈련의 입력 값을 아래와 같이 행렬 로 나타낼 수 있다.
행렬 는 훈련이 개라면 , 개의 열과 개의 행으로 이루어진다.
이며, 이다.
파이썬에서는 X.shape 로 차원을 확인할 수 있다. 위 예시는 X.shape = () 이 된다
또한 전체 훈련의 결과 값을 아래와 같이 행렬 로 나타낼 수 있다.
행렬 는 훈련이 개라면 , 개의 열과 1개의 행으로 이루어진다.
이며, 이다.
마찬가지로 파이썬에서는 Y.shape 로 차원을 확인할 수 있다. 위 예시는 Y.shape = () 이 된다
위처럼, 여러 훈련데이터를 각각의 열로 놓는 것이 유리하다고 한다.
아직은 강의 초반이기 때문에, 직접적인 이유는 강의를 더 들으며 여러 예시를 다루다보면 알게 된다고 한다.
로지스틱 회귀
로지스틱 회귀란 이진 분류를 하기 위해 사용되는 방법이다.
구분을 원하는 사진의 데이터를 , 주어진 데이터()의 실제 값을 , 의 예측 값을 라고 할 때 아래와 같이 표현한다.
•
,
•
→ 가 1일 확률
로지스터 회귀에 앞서, 선형 회귀의 개념과 시그모이드 함수를 이해해야한다.
선형 회귀란?
시그모이드 함수란?
기존의 선형 회귀를 사용하여 예측 값()을 계산하면 로 계산된다.
하지만 이때 가 범위를 넘어서는 경우도 존재한다.
그래서 시그모이드 함수를 사용하여 선형 회귀를 이용한 예측 값의 결과를 로 설정한다.
이렇게 되면 가 만족하게 되면서 예측 값이 얼마나 참, 거짓에 가까운지 확인할 수 있게 된다.
손실 함수와 비용함수
손실함수
손실함수는 하나의 입력 에 대한 실제 값 와 예측 값 의 오차를 계산하는 함수이다.
이 손실함수를 사용하여 알고리즘이 얼마나 잘 동작하는지 수치상으로 확인할 때 사용할 수 있다.
보통은 손실함수의 수식은 를 사용한다. 하지만 지역 최소 값(local minimum)이 발생할 수 있기 때문에 사용하지 않는다.
로지스틱 회귀에서는 를 사용하는 것이 좋다.
위 함수를 2가지 경우로 나누어 확인하면 왜 로지스틱 회귀에서 사용하는지 이해할 수 있다.
1.
일 때, 가 0에 가까워지도록(오차가 적어지도록) 은 0에 수렴하게 된다.
2.
일 때, 가 0에 가까워지도록(오차가 적어지도록) 은 1에 수렴하게 된다.
지역 최소 값이란?
비용함수
손실함수가 하나의 입력에 대한 오차를 계산하는 함수였다면, 비용함수는 모든 입력에 대한 오차를 계산하는 함수이다.
손실함수의 식을 사용하여 개의 입력에 대한 손실을 구하는 비용함수는 아래와 같다.
여기서 , 는 각각 번째 입력, 번째 실제 값, 번째 예측 값을 나타낸다.
경사하강법(gradient descent)
경사하강법은 함수의 기울기를 구하고, 경사의 반대방향으로 계속 이동하여 극값에 이를때까지 반복하는 방법이다.
그럼 이 방법을 왜 사용할까?
우리는 모든 훈련의 오차를 확인하기 위해 를 사용하였다. 이를 그래프로 간단히 나타내면 다음과 같다.
우리는 최상의 훈련 결과를 위해 가장 적은 오차를 가진 를 확인할 필요가 있다.
이때 경사 하강법을 사용하면, 가장 오차가 적은 → 극값을 가지는 입력 과 예측 비용 을 얻을 수 있다.
모든 경우를 확인하여 최소값을 확인하는 방법도 있지만, 이 경우 데이터가 많을 경우 매우 비효율적인 방법이 될 수 있다.
하지만, 경사하강법은 하나의 위치와 해당 함수의 기울기를 이용하여 최소값으로 탐색하는 원리이다.
따라서 굳이 모든 입력의 결과를 연산을 할 필요가 없다.
2차원 그래프를 이용한 예시
실제로는 무조건 2차원으로 표현되지는 않겠지만, 강의에서 개념 설명을 위해 2차원을 예시로 들어주었다.
예시처럼 비용함수가 볼록한 형태여야만 경사하강법을 이용할 수 있다.
•
예시 그래프 사진
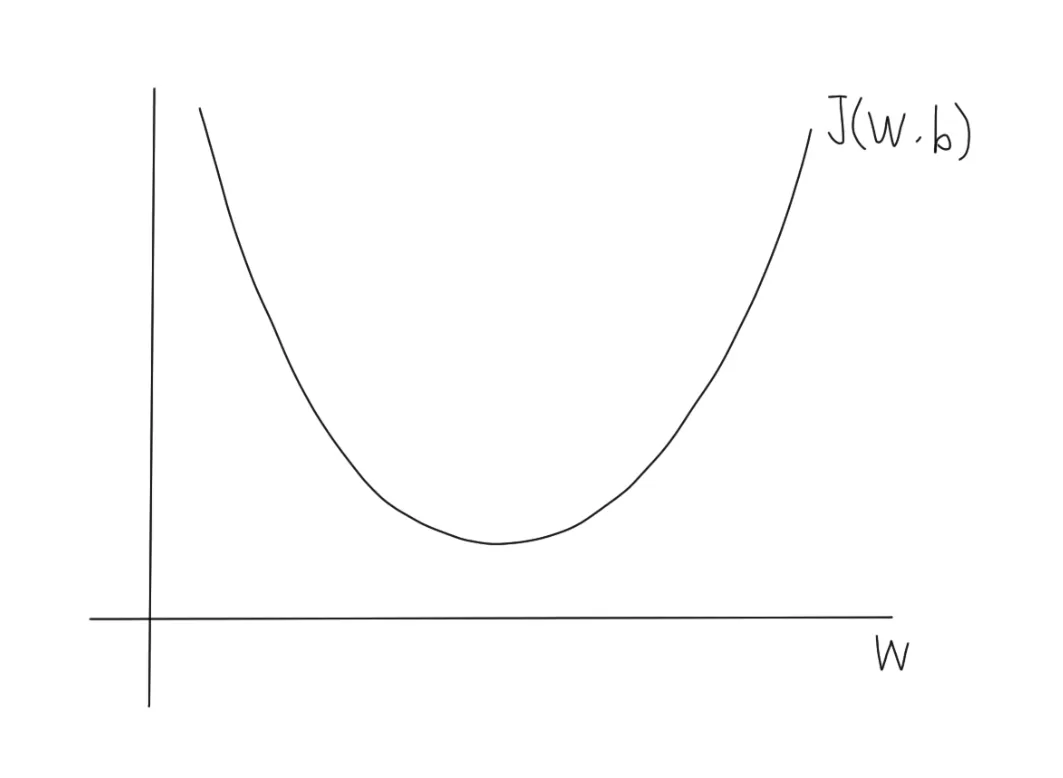
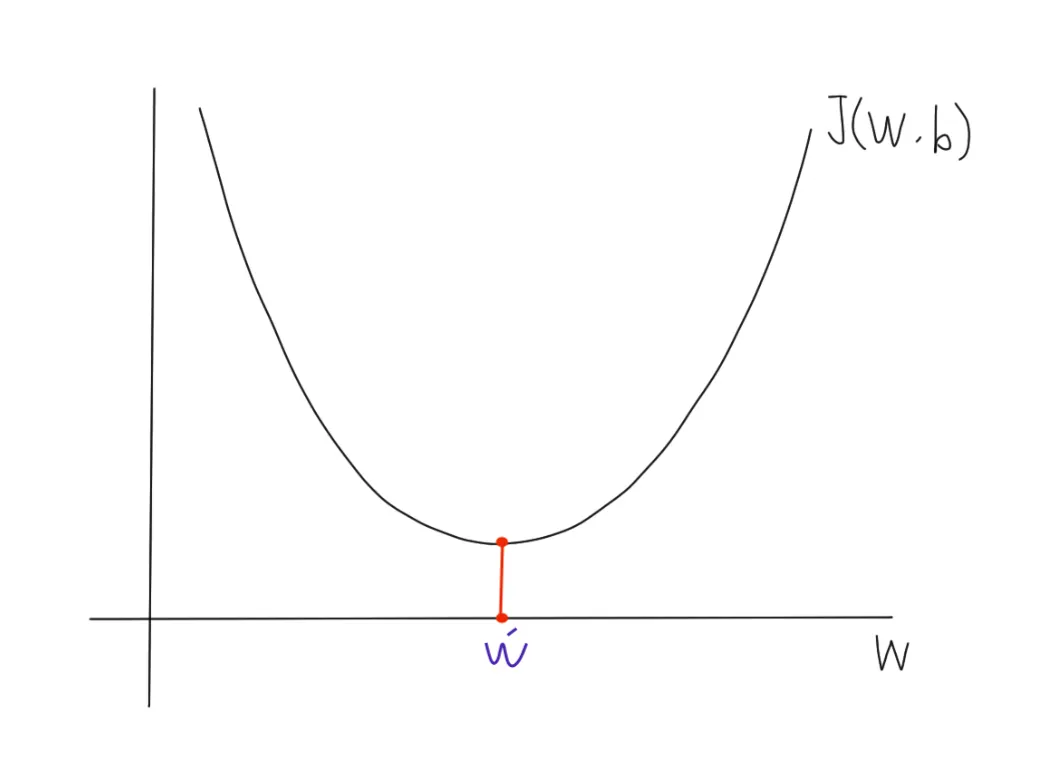
•
예측 값이 실제 값과 가장 적은 오차를 가진 입력 ()
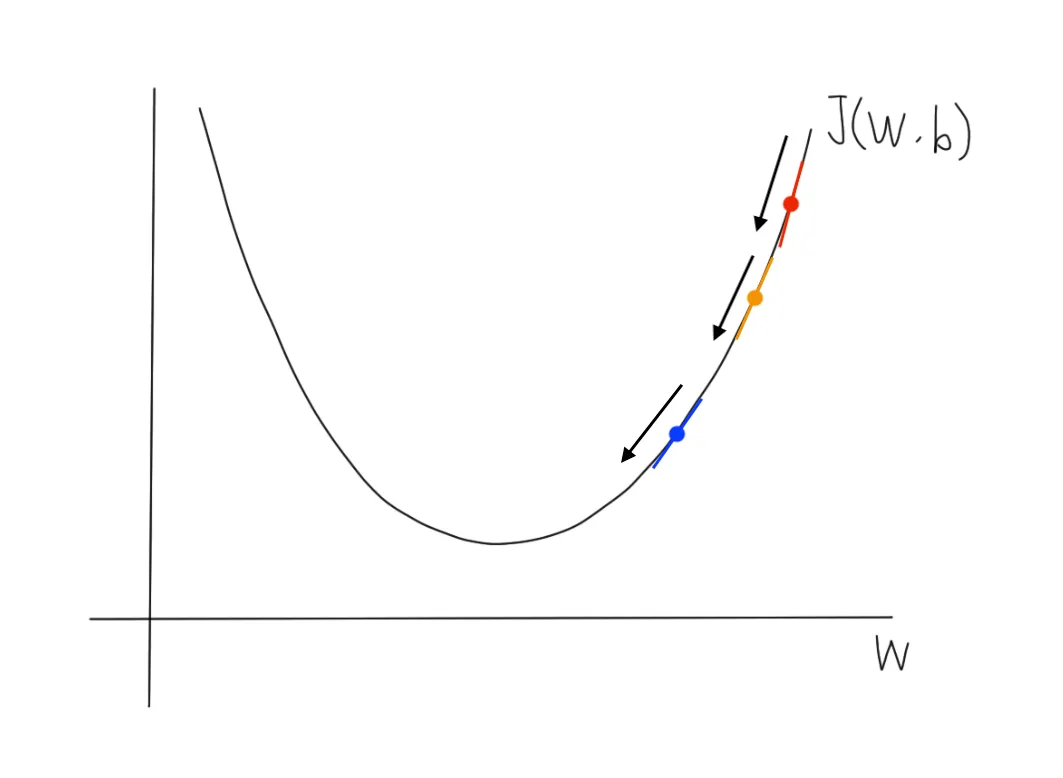
위 내용처럼 경사하강법은 가장 가파른 방향으로 함수의 기울기를 따라서 최소값으로 한번씩 업데이트 한다.
•
알고리즘
◦
◦
•
설명
◦
는 학습률을 나타낸다.
▪
는 정해져 있는 값은 없고, 테스터가 임의로 설정한다.
▪
가 크다면 → 더 적은 횟수로 최적의 파라미터에 가까워질 수 있으나, 최적의 파라미터를 넘겨 발산할 수 있음
▪
가 작다면 → 더 많은 횟수로 최적의 파라미터에 다가가야하지만, 더 섬세하게 최적의 파라미터로의 조절이 가능
◦
는 도함수이며, 미분을 통해 구한값이다. 로 표기하기도 한다.
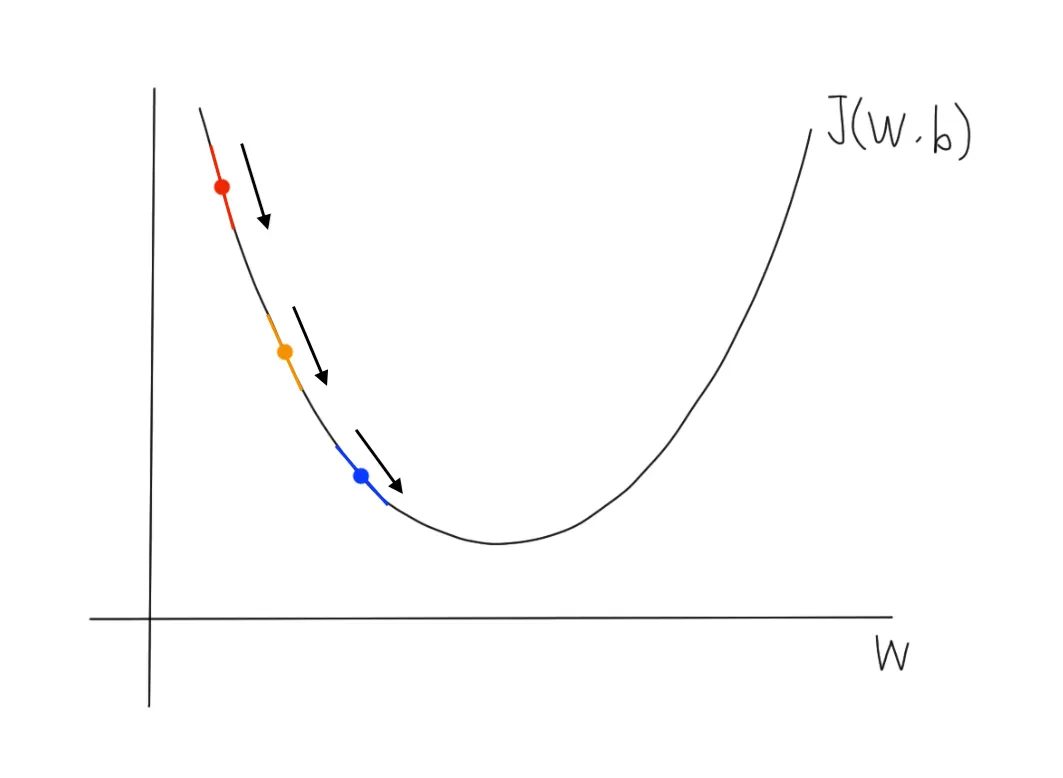
이때 값에 따라 처음 설정한 값이 어느 방향으로 이동할지 정해진다.•
이 되며, 기존의 보다 작은 값의 로 업데이트 된다.
•
이 되며, 기존의 보다 큰 값의 로 업데이트 된다.
도함수의 표기법
위에서부터 계속 사용한 는 하나의 변수에 대해서만 사용하는 표기법이다.
이때 두 개이상(여러 개)의 변수에 대해 도함수를 표현할 때는 로 표기한다.
계산 그래프를 이용한 정방향 전파 / 역방향 전파
계산 그래프는 계산 과정을 그래프로 표현한 것으로, 특정한 출력값 변수를 최적화할 때 유용하다.
이러한 계산 그래프는 로지스틱 회귀에서는 최종결과인 (비용함수)의 최적화를 위해 사용한다.
라는 예시가 존재한다. 이때 이 계산과정을 아래와 같이 나타낸다고 해보자.
•
•
•
•
예시의 계산 그래프
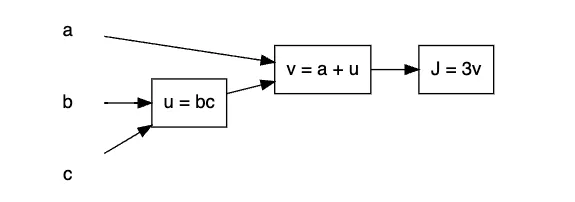
위와 같이 계산 그래프가 표현된다면, 당연히 기본적인 계산은 아래 순서대로 진행할 것이다.
1.
값을 이용하여 값을 구한다.
2.
값을 이용하여 값을 구한다.
3.
마지막으로, 값을 이용하여 값을 구한다.
이렇게 최종적인 결과를 얻기 위해 순차적으로 계산하는 방법을 정방향(순방향) 전파(Forward Propagation)이다.
이를 신경망에 적용한다면 을 포함한 여러 입력과 정방향 전파를 이용해 예측 값을 구한다.
이를 통해 해당 훈련의 예측 값이 실제 값과 얼마나 차이나는지 (손실함수)를 통해 확인할 것이다.
여기서 당연하게도 정방향 전파로 구한 예측 값이 실제 값과의 차이가 최대한 적어야 할 것이다.
이를 위해 정방향 전파에 사용되는 등 입력들을 훈련마다 개선한 값으로 변경할 필요가 있다.
이때 사용되는 것이 역방향 전파(오차 역방향 전파)(Back Propagation)이며, 정방향 전파와는 반대방향으로 진행한다.
역방향 전파는 예측 값을 구하는 정방향 전파와는 다르게, 각 계산의 도함수를 구한다.
이 도함수는 각 단계의 가중치와 편향등을 개선하는데 사용되어 다음 정방향 전파로 예측 값을 구할 때 실제 값에 더욱 근접하도록 도와준다.
이전 정방향 전파의 예시를 사용하여, 역방향 전파의 예시를 들기전에 몇 가지 알아야 할 내용이 있다.
바로 코드 작성 시 도함수의 표기법과 미분의 연쇄법칙이라는 내용이다.
코드 작성 시 도함수의 표기법
이전에 도함수를 형태로 많이 봤을텐데, 이는 를 에 대해 미분하는 것을 의미한다.
여기서 왜 를 붙이는지 궁금할텐데, 여기서 는 미분의 머릿글자를 나타낸다.
여기서 는 의 미분소(무한소)를 나타내며, 이말은 의 정말 상상할 수 없을 정도로 작은 변화를 말하는 것이다.
그렇다면 우리가 써왔던 의 의미도 자연스럽게 이해가 될것이다.
의 변화 의 변화 → 즉, 우리가 알던 도함수(기울기)가 되는것이다.
이제 코드나 예시를 보면서 복잡한 형태의 도함수 값을 볼텐데, 아래의 규칙으로 표기할것이다.
미분의 연쇄법칙
미분의 연쇄법칙은 합성함수의 도함수를 구하기 위한 공식이다. 설명을 위해 이전에 정방향 전파 때 사용했던 예시 그래프를 살펴보자
여기서 는 최종 결과 에 도달하기 위해 → → 순서로 계산이 진행된다.
즉, 를 기준으로 가 된다.
•
정방향 전파 예시 그래프
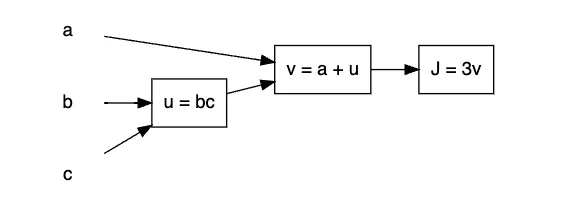
이때 이 합성함수 를 로 미분한 값인 는 로 표현된다.
즉, 합성함수는 여러 함수가 결합하여 만들어진 함수이기 때문에 이 합성함수의 미분은 각 합성함수의 곱으로 나타낼 수 있다.
이를 미분의 연쇄법칙이라고 한다. 이는 역방향 전파에서 다음 단계의 도함수를 사용할 때 쓰인다.
역방향 전파의 예시 (도함수 구하기)
이전 정방향 전파에서 사용된 동일한 노드를 이용하여 예시를 들어보겠다. 역방향이기 때문에, 아래 순서로 도함수를 구해볼 수 있다.
•
역방향 전파 예시 그래프
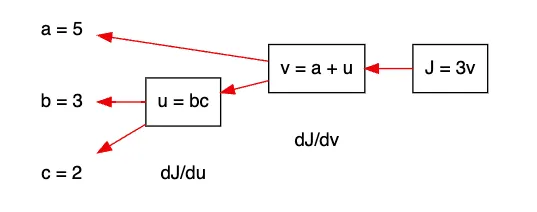
•
예시에서 역방향 전파로 도함수를 구하는 순서
1.
를 구한다.
2.
1번 결과를 사용해 혹은 를 구한다.
3.
2번의 를 이용하여 를 계산한다.
1번 과정 ( 구하기)
2번 과정 ( 구하기)
2번 과정( 구하기)
3번 과정( 구하기)
3번 과정(구하기)