
이 페이지는 OpenAI의 공식 문서 중, 기능 설명 부분을 정리한 내용입니다.
모든 내용이 정리되어 있지는 않으며, 개인적인 공부를 진행하며 필요한 내용을 번역하여 정리했습니다.
OpenAI 기능 설명 공식문서 (Documentation)


OpenAI API란?
공식문서에 작성되어 있는 OpenAI에 대한 소개는 아래와 같습니다.
OpenAI API는 자연어, 코드 또는 이미지를 이해하거나 생성하는 것과 관련된 거의 모든 작업에 적용할 수 있습니다.
특정 작업을 위한 여러 성능의 다양한 모델과 “Fine-Tune” 이라는 기능을 사용하여 원하는 커스텀 모델을 만들 수 있는 기능을 지원합니다.
알아두면 좋은 키워드
앞으로 공식 문서를 보면서, 자주 등장하는 키워드에 대한 내용입니다.
공식 문서에서도 별도로 정리하여 언급하는 만큼, 숙지 후 문서를 읽으시면 도움이 될 것 같습니다.
Prompts
프롬포트(Prompt)란, 우리가 현재 많이 사용하는 ChatGPT와 같은 대규모 언어 모델(LLM)에서 사용하는 입력 값입니다.
Prompt Engineering, Prompter 등 용어가 있을 정도로, LLM의 퀄리티는 Prompt가 큰 영향을 준다고 해도 과언이 아닙니다.
우리가 Prompt를 잘 디자인하여 사용한다면 단순한 자연어 처리(NLP)를 넘어, 콘텐츠 생성 / 요약 / 확장 / 대화 / 창작 등 수 많은 작업에 사용될 수 있는 모델을 만들어낼 수 있습니다.
OpenAI사에서 제공하는 Prompt 디자인에 대한 간단한 정리 내용입니다.
https://platform.openai.com/docs/guides/completion/prompt-design
Tokens
OpenAI사에서 제공하는 많은 모델들은 입력된 대량의 Text를 “Token” 이라는 단위로 나누어 처리합니다.
영어를 기준으로, 1토큰 → 4글자 / 0.75단어 정도라고 합니다.
현재 OpenAI 제공되는 Model은 대부분 2048 토큰 / 약 1500단어를 넘기면 처리할 수 없습니다. 모델마다 다를 수 있으니 사용 시 이 점을 숙지하면 좋을 것 같습니다. (Token을 기준로 API 사용 비용 청구 )
)아래 링크를 참고하시면, API를 호출하지 않고도 메세지의 토큰을 계산할 수 있는 코드를 확인할 수 있습니다.

Models
OpenAI사에서는 사용자의 목적에 맞는 모델을 만들 수 있도록 Fine-Tuning을 할 수 있는 다양한 모델을 제공합니다.
각 모델마다 토큰별 가격과 성능, 목적이 다르니 아래 사이트를 참고 후 사용하면 좋습니다.
OpenAI사에서 제공하는 Model에 대한 간단한 정리 내용입니다.
https://platform.openai.com/docs/models
기능 간단 정리
OpenAI사의 API로 제공해주는 여러 기능에 대한 정리입니다.
실제 사용법 및 코드 확인을 원하신다면, 아래 페이지로 이동해주세요 :)
OpenAI Playground
OpenAI사는 자사의 기능을 웹 페이지상에서 테스트해볼 수 있도록, Playground를 제공하고 있습니다.
간단한 테스트 시 사용하면 좋습니다.


단, OpenAI 사용을 위한 카드 연결이 필요하며 많은 데이터(token)를 다루는 테스트를 반복 시 많은 비용이 청구될 수 있습니다.
간단 사용법
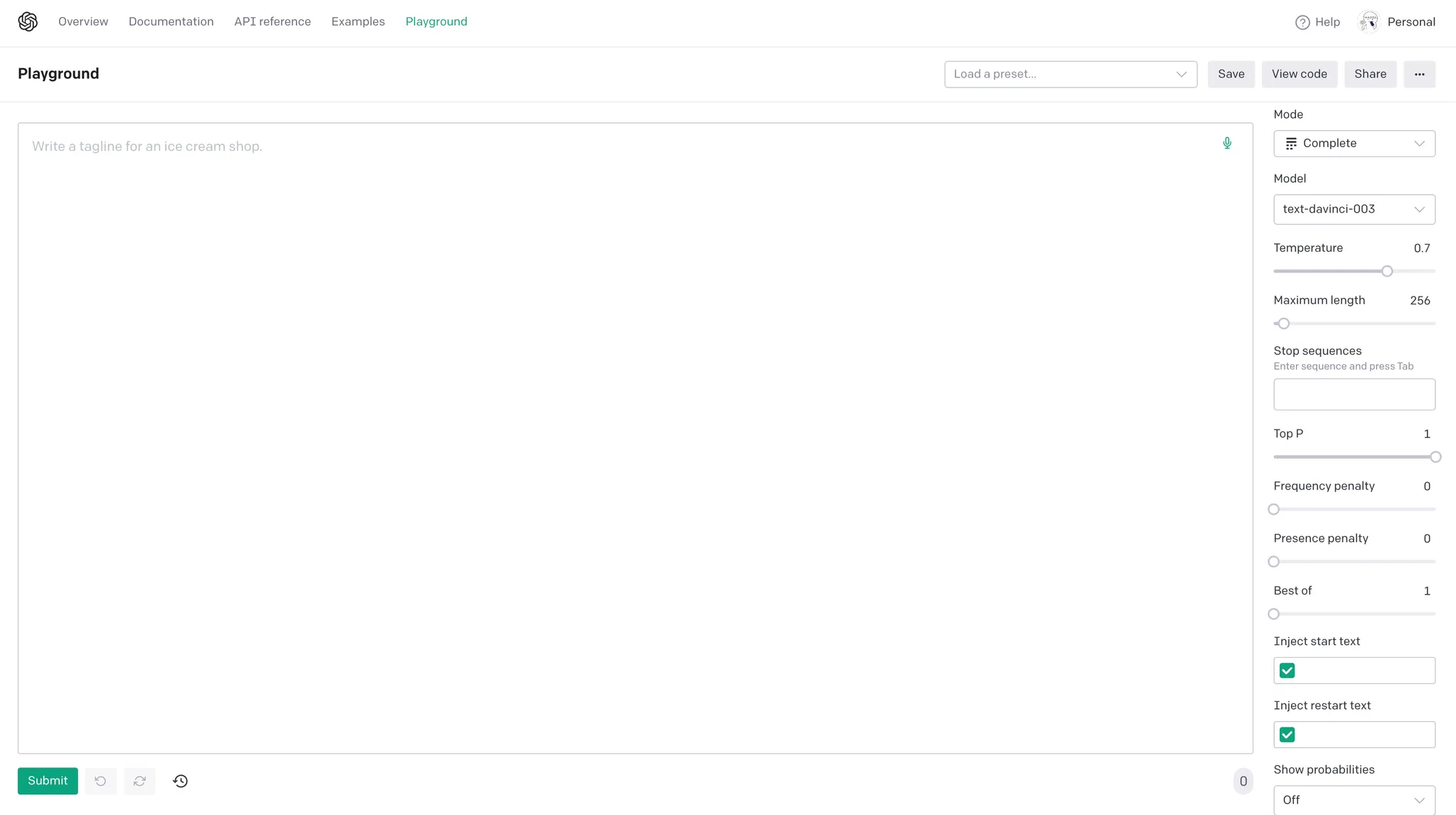
OpenAI Playground 전체 화면
•
상단 리스트 / 버튼 설명
◦
Load a preset… : 다양한 예시를 불러올 수 있는 리스트
◦
Save : 현재 Playground를 preset으로 저장
◦
View Code : 현재 preset을 코드로 작성하는 법을 보여줌
◦
Share : 현재 Playground를 preset으로 공유
•
우측 설정 설명
Name | 기능 |
Mode | 테스트로 사용할 수 있는 기능을 확인 가능 |
Model | 테스트에 사용될 모델 |
Temperature | 결과 값의 다양성 수치 (0 ~ 1)
0 → 다양성이 낮음
1 → 다양성 높음 |
Maximum length | 결과 값의 최대 토큰 수
만약 결과 값의 Token이 해당 값보다 클 경우, 해당 값만큼의 Token만 출력 |
Top P | 결과 값의 단어 사용의 일관성 수치 (0 ~ 1)
0 → 다양성이 높아지며, 결과 값에서 사용되는 텍스트가 다양해짐
1 → 일관성이 높아지며, 결과 값에서 사용되는 텍스트가 덜 다양해짐 |
Frequency Penalty | 이전에 사용된 Token의 사용 가능성 (0 ~ 1)
0 → 이전에 사용된 Token 및 자주 사용된 Token의 사용 가능성이 높아짐
1 → 이전에 사용된 Token 및 자주 사용된 Token의 사용 가능성이 낮아짐 |
Presence Penalty | 이전에 사용된 Token의 사용 가능성 (0 ~ 1)
0 → 이전에 사용된 Token의 중복 가능성이 높아짐
1 → 이전에 사용된 Token의 중복 가능성이 낮아짐 |
Best of | 각 프롬프트에 대해 생성할 수 있는 후보 응답 중 최상의 n 개를 반환 (1 ~ 20) |
Inject start text | 결과 값에 시작 단어 |
Inject restart text | 재 요청 시 Prompt의 시작 단어 |
Show probabilities | Playground 페이지에서만 사용하는 옵션으로, 토큰에 대한 강조 표시 설정 |
Text Completion
해당 기능은 곧 지원 종료 예정 → Chat Completion 사용 권장
Completion 이란 결과 값 같은 느낌입니다.
Complete(완료)라는 단어에 tion 이라는 접미사를 붙여 명사로 만든 단어니까요.
Text Completion은 하나의 Prompt → 하나의 결과 값 출력을 진행하는 방식이라는 것입니다.
Prompt : A 해줘
Response : 네, 결과문은 …이고, … 입니다.
Plain Text
복사
즉, 우리가 평소 ChatGPT를 사용하는 것처럼 이전에 사용한 Prompt를 재사용하여 정말 “대화” 하는 방식으로 사용하고 싶다면, Chat Completion을 사용해야 합니다.
물론, Prompt내 대화 내용을 규격에 맞게 처리할 수 있도록 기록을 넣어준다면 가능합니다.
하지만, 1회 처리 가능한 token수의 초과와 규격 처리를 위한 복잡한 설정이 필요하기 때문에 Chat Completion을 사용을 권장합니다.
예시
잘 알려진 “토끼와 거북이” 이솝 우화에서 얻을 수 있는 교훈을 한줄로 작성해달라는 Prompt를 사용한 예시이며, 별도의 Fine-Tuning을 하지 않은 기본 제공 모델을 사용하였습니다.
초록색으로 표시된 부분이 Response된 내용입니다.

Chat Completion
일반적인 지시문 하나만 동작하는 Text Completion과 다르게, 대화형으로 답변을 받을 수 있는 방법입니다.
그럼 Text Completion이 아닌, Chat Completion을 사용하면 되는 것 아닐까라는 생각이 들 수 있습니다.
하지만, Chat Completion에서는 Text Completion에 없는 단점이 하나있습니다. 바로 사용 가능한 모델을 Fine Tuning 할 수 없다는 점입니다.
사용가능한 모델 중 대표적인 모델은 gpt-3.5-turbo 가 있습니다.
Chat Completion은 메세지를 다루는 주체를 다르게 설정할 수 있는데, 이를 role 이라고 합니다.
role은 system, user, assistant 총 3가지가 존재합니다.
role을 설정하고, 아래와 같이 content를 설정합니다. 이러한 데이터가 모여 하나의 대화가 만들어집니다.
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
Python
복사
System Role
Chat을 진행하면서, 시스템에 대한 컨셉(?)을 설정하는 내용입니다.
예를 들어 “~~와 같이 답변하라” 라고 설정 후 시작하면, 해당 내용에 맞게 내용이 설정됩니다.
하지만, OpenAI사는 아래와 같은 내용을 작성해두었습니다.
간단하게 요약하면, System Role에 설정한 내용이 있어도 User Role에서 System Role에 맞지 않는 내용을 작성하면 System Role의 내용을 무시하고 결과를 반환해줍니다.
In general, gpt-3.5-turbo-0301 does not pay strong attention to the system message, and therefore important instructions are often better placed in a user message.
이에 대한 내용을 다룬 글도 있긴한데, 기본적으로 gpt-3.5-turbo-0301 모델은 User Role의 메세지이 결과 메세지 생성에 큰 영향을 주는 것이라고 알면 좋을 것 같습니다.

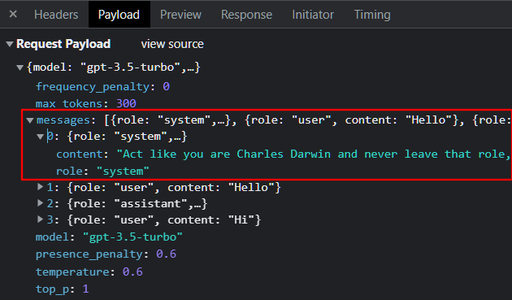
User Role
사용자가 질문하고 싶은 내용을 작성하는 내용입니다.
Assistant Role
모델에서 얻은 답변이 기록되는 곳입니다. 위에서 사용한 예시를 사용하면 이해가 쉽습니다.
API를 사용한 데이터 전달 시
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
Python
복사
데이터에 따른 실제 대화 상황
System : You are a helpful assistant.
User : Who won the world series in 2020?
Assistant(답변) : The Los Angeles Dodgers won the World Series in 2020.
User : Where was it played?
Assistant(답변) : ...
Plain Text
복사
Fine Tuning
간단하게 설명하면, 사용자가 원하는 답변에 주기위한 모델을 만들기 위해 학습을 진행시키는 것이라고 할 수 있습니다.
순서는 아래와 같이 진행됩니다.
1.
Prepare and upload training data → 학습 데이터 준비 및 업로드
2.
Train a new fine-tuned model → 새로운 Fine-Tuned 모델 학습
3.
Use your fine-tuned model → 학습된 Fine-Tuned 모델 사용
여기서 주의할점은 davinci, curie, babbage, ada 모델에서만 Fine-Tuning이 가능합니다.
gpt-3.5-turbo-0301, gpt-4 모델은 Fine-Tuning이 불가능합니다.
학습 데이터 준비
아래 작업은 설명만 존재하며, 실제 코드 및 상세 진행 내용은 아래 페이지를 확인해주세요 :)
먼저 JSONL 형식의 파일에 prompt-completion 쌍으로 이루어진 데이터를 설정합니다.
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
Plain Text
복사
JSON vs JSONL
이후 OpenAI에서 제공하는 데이터 전처리 툴을 사용하여, Fine-Tuning에 적합한 데이터로 변환해줍니다.
이때 CSV, TSV, XLSX, JSON, JSONL 파일에 해당 툴을 사용하면, Fine-Tuning에 적합한 데이터로 변환된 JSONL 파일을 반환해줍니다.
이후 변환된 훈련 데이터 파일을 업로드 후, 모델에 학습을 진행합니다.
Embedding
…
Image Generation
…