해당 페이지는 시중에 판매되고 있는 파이썬 머신러닝 판다스 데이터 분석 책을 정리한 내용이 많습니다.
 설치
설치
pip3 install pandas
Bash
복사
공식 문서
기초 내용
Series
데이터가 순차적으로 나열된 1차원 배열이다. 기존 파이썬의 딕셔너리와 비슷한 구조이며 반복 가능한 객체 데이터를 Series로 변환이 가능하다.
DATA → Series
pandas.Series(data) 형태로 변환이 가능하다.
data 에는 array-like, Iterable, scalar value 가 가능하다.
[+] Iterable(반복 가능 객체) : list, dict, set, str, bytes, tuple, range 가 대표적이다.
[+] 또한 dict를 이용하여 변환 시, 인수 순서가 유지된다.
예시Series의 index, value 값 따로 확인
•
인덱스 배열 반환 : Series.index
•
데이터 값 배열 반환 : Series.values
예시원하는 인덱스 값 설정
튜플, 리스트 형태 데이터를 Series로 변환 시 인덱스가 지정되어 있지 않기 때문에 index 인자 값으로 설정이 가능하다.
예시원하는 원소 확인
기존 파이썬의 리스트처럼 Series[index] 형태로 원소 확인이 가능하다.
또한 index 에 따라 원하는 원소의 범위를 지정할 수 도 있다.
예시Series 연산
•
pandas.Series + (연산자) + 숫자
•
pandas.Series + (연산자) + pandas.Series
Series 객체끼리 연산 시 일대일로 대응하여 연산을 한다.
이때 일대일로 대응되는 원소가 없거나, 길이가 다를 경우 NaN 으로 값을 처리한다.
NaN 값은 어떤 값과 연산을 해도 NaN 이다.
[+] 같은 이름의 원소끼리 연산
[+] 정수형 원소일 경우 그냥 연산
예시함수를 사용하여 연산 시, fill_value 옵션을 사용(필수 X) 하면 NaN 인 값을 원하는 값으로 변경 후 계산해준다.
•
덧셈 : Series.add(Series2, fill_value=data)
•
뺄셈 : Series.sub(Series2, fill_value=data)
•
곱셈 : Series.mul(Series2, fill_value=data)
•
나눗셈 : Series.div(Series2, fill_value=data)
예시2 DataFrame
DataFrame은 행과 열로 이루어진 2차원 배열이다. 여러 시리즈가 모여서 만들어지는 구조로 2차원 벡터 / 행렬 구조이다.
DATA → DataFrame
pandas.DataFrame(data) 형태로 변환이 가능하다.
data 에는 ndarray (structured or homogeneous), Iterable 등이 가능하다.
[+] Iterable(반복 가능 객체) : list, dict, set, str, bytes, tuple, range 가 대표적이다.
[+] 또한 dict를 이용하여 변환 시, 인수 순서가 유지된다.
예시DataFrame 행과 열 변경
•
행 변경
◦
DataFrame.index=[1차원 배열]
◦
DataFrame.rename(index={before:after, ...}, inplace=[True/False])
•
열 변경
◦
DataFrame.columns=[1차원 배열]
◦
DataFrame.rename(columns={before:after, ...}, inplace=[True/False])
DataFrame.rename() 함수의 inplace 인자 값은 원본 변경 유무입니다.
True 일 경우 → 원본의 행 / 열 변경 후 반환하지 않음(None)
False 일 경우 → 원본의 데이터를 변경하지 않고, 변경된 DataFrame을 반환
예시 예시2DataFrame 행과 열 삭제
DataFrame.drop(labels, axis=[0/1], inplace=[True/False]) 함수를 사용한다.
•
labels : 삭제할 이름이나 번호가 들어간다.
•
axis : axis가 0 일 경우 행을 삭제, axis가 1 일 경우 열을 삭제
•
inplace
◦
원본데이터 수정을 원하면 True
◦
수정된 DataFrame을 반환 받고 원본은 건들지 않을려면 False
예시DataFrame 행과 열 그리고 원소 선택
•
행 선택
◦
DataFrame.loc['index_name']
◦
DataFrame.iloc['index_num']
•
열 선택
◦
DataFrame['column_name']
◦
DataFrame.column_name
•
원소 선택
◦
DataFrame.loc['index_name', 'column_name']
◦
DataFrame.iloc['index_num', 'column_num']
예시DataFrame 행과 열 추가
•
행 추가
◦
DataFrame.loc['new_index_name'] = data
◦
DataFrame.iloc[new_index_num] = data
•
열 추가
◦
DataFrame['new_column_name'] = data
예시DataFrame 특정 원소 변경
•
DataFrame.loc['index_name']['column_name']
•
DataFrame.iloc[index_num][column_num]
예시DataFrame 행 / 열 바꾸기
아래 함수를 사용하여 행 값을 열 값으로, 열 값을 행 값으로 뒤 바뀐 DataFrame을 반환받을 수 있다.
두 방법 중 편한 방법 하나를 택하면 된다.
•
DataFrame.transpose()
•
DataFrame.T
예시DataFrame INDEX 설정 / 재설정 / 리셋
DataFrame에 존재하는 Index를 설정한다.
•
특정 Column을 Index로 설정 후 반환
◦
DataFrame.set_index(['column_name'])
◦
inplace 옵션을 사용할 수 있다.
•
특정 데이터를 Index로 재 설정 후 반환
◦
DataFrame.reindex([data, data2, ...])
◦
기존에 존재하지 않던 인덱스 행 데이터는 모두 NaN 으로 채워진다.
•
DataFrame의 Index를 정수형으로 초기화 후 반환
◦
DataFrame.reset_index()
예시DataFrame 정렬
인덱스 / 컬럼 / 데이터 값을 오름차순 / 내림차순 정렬이 가능하다. 또한 inplace 옵션도 사용 가능하다.
•
인덱스 / 컬럼 정렬
◦
DataFrame.sort_index(axis=[0 / 1], ascending=[True / False])
◦
axis 값이 0일 경우 인덱스를 정렬하며, axis 값이 1일 경우 컬럼을 정렬한다.
◦
ascending 값이 True 일 경우 오름차순, False 일 경우 내림차순으로 정렬한다.
•
데이터 값 정렬
◦
DataFrame.sort_values(axis=[0 / 1], by='str' ,ascending=[True / False])
▪
axis 값이 0일 경우 인덱스를 기준으로 하며, axis 값이 1일 경우 컬럼을 기준으로 한다.
▪
ascending 값이 True 일 경우 오름차순, False 일 경우 내림차순으로 정렬한다.
▪
by 값에 따라 정렬한다.
예시DataFrame 연산
•
DataFrame + (연산자) + value
•
DataFrame + (연산자) + DataFrame
예시 Pandas Option 변경
출력 옵션 변경
Series나 DataFrame을 출력할 때 옵션을 변경할 수 있다. 보통 많은 데이터를 출력할 때는 ... 으로 표시되어 일부만 보이는데, 그 부분을 변경할 수 있다.
•
출력 가능한 행 수 변경(None은 무제한)
pd.set_option('display.max_rows', None)
•
출력 가능한 컬럼 수 변경(None은 무제한)
pd.set_option('display.max_columns', None)
•
출력 가능한 가로 길이 변경(None은 무제한)
pd.set_option('display.width', None)
•
출력 가능한 컬럼 width 변경(-1은 무제한)
pd.set_option('display.max_colwidth', -1)
더 많은 옵션은 아래 정식 문서에서 확인 가능하다.
데이터 확인
DataFrame 일부 내용 확인
•
첫 5행만 표시 : DataFrame.head()
•
마지막 5행 표시 : DataFrame.tail()
DataFrame.head(num) 처럼 숫자를 넣어 원하는 행 수 만큼 확인도 가능하다.
예시DataFrame 정보 확인
•
DataFrame 행 / 열 갯수 확인
◦
DataFrame.shape → ( 행, 열 ) 로 반환
•
DataFrame 기본 정보 출력
◦
DataFrame.info()
•
DataFrame 통계 정보 출력
◦
DataFrame.describe() → 데이터가 NaN 인 행은 출력하지 않는다.
◦
DataFrame.describe() → 데이터가 NaN 인 행도 출력한다.
DataFrame 열의 데이터 갯수
•
각 열의 데이터 갯수
◦
DataFrame.count()
NaN 이 아닌 데이터가 존재하는 열의 갯수만 측정한다.
•
각 열의 고유 값 개수
◦
DataFrame['column_name'].value_counts()
dropnan 옵션을 True로 설정하면 NaN 갯수를 측정하지 않으며, False로 설정하면 NaN 갯수를 측정한다.
DataFrame 통계 기능 사용
•
평균 값 구하기
◦
DataFrame.mean()
◦
DataFrame['column_name'].mean()
•
중간 값 구하기
◦
DataFrame.median()
◦
DataFrame['column_name'].median()
•
최대 값 구하기
◦
DataFrame.max()
◦
DataFrame['column_name'].max()
•
최소 값 구하기
◦
DataFrame.min()
◦
DataFrame['column_name'].min()
•
표준편차 값 구하기
◦
DataFrame.std()
◦
DataFrame['column_name'].std()
•
상관계수 값 구하기
◦
DataFrame.corr()
◦
DataFrame['column_name'].corr()
시각화 도구
Matplotlib, Seaborn, Folium 등 라이브러리가 존재한다.
Matplotlib 라이브러리
Matplotlib 라이브러리의 그래프 사용법
아래 링크에 Matplotlib의 그래프에 대한 자세한 소개가 있는데, 이 책에서는 이 내용에 대한 자세한 소개를 하지 않아 링크를 남긴다.

Matplotlib의 객체지향 API 를 사용하여 그래프 출력 예시
Matplotlib는 두가지 방식의 API를 제공하고 있고, Pyplot API와 객체지향 API 중 선택하여 사용가능하다.
상세한 그래프 설정을 위해서는 객체지향 API를 사용한다고 한다.
1.
Figure 객체를 생성
import matplotlib.pyplot as plt
import numpy as np
...
# Figure 객체 생성
fig = plt.figure()
Python
복사
2.
이를 이용해 하나 이상의 Axes 객체를 생성
import matplotlib.pyplot as plt
import numpy as np
...
# Figure 객체 생성
fig = plt.figure()
# Figure 객체를 이용하여 Axes 객체를 생성
ax = fig.subplots()
Python
복사
3.
Axes 객체의 헬퍼함수로 primitives를 생성
import matplotlib.pyplot as plt
import numpy as np
...
# Figure 객체 생성
fig = plt.figure()
# Figure 객체를 이용하여 Axes 객체를 생성
ax = fig.subplots()
# Axes 객체의 헬퍼함수로 primitives를 생성
ax.plot(x_data,y_data,'r-*',lw=1)
Python
복사
Axes 객체 헬퍼함수(plot())의 3번째 인자(r-*) 값은 그래프의 꾸미기에 사용되는 인자이다.
또한 lw는 line width 이다.
그래프의 꾸미기에 대한 정보는 아래 링크에서 확인할 수 있다.

subplots를 이용하여 간편하게 서브 그래프를 작성하기
위 예시에서 Figure 객체 생성 후, Axes 객체를 생성하여 각 Axes 객체를 설정한다고 하였다.
이때 Figure 객체와 Axes를 각각 생성하는게 불편하다. 그래서 subplots() 함수를 사용하여 간편하게 정의하고 관리할 수 있다.
•
Figure 객체와 Axes를 각각 생성하는 기존 방식
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0,1,50)
y1 = np.cos(4*np.pi*x)
y2 = np.cos(4*np.pi*x)*np.exp(-2*x)
# Figure 객체 생성
fig = plt.figure()
# Figure 객체를 이용하여 1번째 Axes 객체를 생성
ax = fig.add_subplot(2,1,1)
# Axes 객체의 헬퍼함수로 primitives를 생성 후 설정
ax.plot(x,y1,'r-*',lw=1)
ax.grid(True)
ax.set_ylabel(r'$sin(4 \pi x)$')
ax.axis([0,1,-1.5,1.5])
# Figure 객체를 이용하여 2번째 Axes 객체를 생성
ax = fig.add_subplot(2,1,2)
# Axes 객체의 헬퍼함수로 primitives를 생성 후 설정
ax.plot(x,y2,'b--o',lw=1)
ax.grid(True)
ax.set_xlabel('x')
ax.set_ylabel(r'$ e^{-2x} sin(4\pi x) $')
ax.axis([0,1,-1.5,1.5])
fig.tight_layout()
plt.show()
Python
복사
•
subplots() 함수를 사용하여 한번에 정의하고 관리하는 방식
배열처럼 개별적으로 관리하기 때문에 가독성이나 관리가 편하다(개인적으론?)
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0,1,50)
y1 = np.cos(4*np.pi*x)
y2 = np.cos(4*np.pi*x)*np.exp(-2*x)
# subplots 함수를 사용하여 Figure 객체 생성과 Axes 객체을 동시에 가능하다.
# subplots의 인자값을 설정하여 갯수 설정이 가능하다.
# pyplot.subplots(nrows=1, ncols=1, ...)
# source : https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplots.html#matplotlib.pyplot.subplots
fig,ax = plt.subplots(2,1)
# 첫번째 Axes 객체의 헬퍼함수로 primitives를 생성 후 설정
ax[0].plot(x,y1,'go--',lw=1)
ax[0].grid(True)
ax[0].set_ylabel(r'$sin(4 \pi x)$')
ax[0].axis([0,1,-1.5,1.5])
# 두번째 Axes 객체의 헬퍼함수로 primitives를 생성 후 설정
ax[1].plot(x,y2,'b--o',lw=1)
ax[1].grid(True)
ax[1].set_xlabel('x')
ax[1].set_ylabel(r'$ e^{-2x} sin(4\pi x) $')
ax[1].axis([0,1,-1.5,1.5])
plt.tight_layout()
plt.show()
Python
복사
그래프 종류 선택 (kind option)
x , y 옵션을 사용하여 직접 x축, y축 값을 설정할 수 있다.
판다스 내장 그래픽과 비슷하다.
•
선 그래프 : DataFrame.plot(X_DATA,Y_DATA)
◦
연속적인 값과 패턴을 확인할 때 유용하다.
◦
kind 옵션을 설정해주지 않으면 기본적으로 선 그래프이다.
•
면적 그래프 : DataFrame.plot(kind='area')
◦
선 그래프와 X축 간의 면적에 색깔을 입혀 면적을 확인하는 방식
▪
stacked 옵션 True : 누적 사용(다른 열의 선 그래프 위에 쌓이는 방식)
▪
stacked 옵션 False : 누적 미사용
•
수직 막대 그래프 : DataFrame.plot(kind='bar')
◦
데이터 크기에 비례한 높이를 가지는 직사각형의 막대의 상대적 길이 차이를 통해 데이터를 비교
•
수평 그래프 : DataFrame.plot(kind='barh')
◦
데이터 크기에 비례한 높이를 가지는 직사각형의 막대의 상대적 길이 차이를 통해 데이터를 비교
•
히스토그램 : DataFrame.plot(kind='his')
◦
변수가 하나인 단변수의 데이터를 데이터의 크기에 따라 여러 구간으로 나눈뒤(X축) 각 구간에 속한 값의 개수를 확인하기 위해 사용
•
산점도 그래프 : DataFrame.plot(kind='scatter')
◦
연속된 값을 가지는 서로 다른 두 변수의 관계를 표현하기 위한 그래프이다. 두 변수를 각 X축, Y축에 설정한 뒤 선 대신 점으로 구간을 표현한다.
•
고밀도 산점도 그래프 : DataFrame.plot(kind='hexbin')
•
파이 그래프 : DataFrame.plot(kind='pie')
◦
하나의 특정 변수를 데이터 값에 따라 여러 구간으로 나눈 후(히스토그램과 비슷) 해당 구간에 속하는 데이터 값의 개수를 하나의 원에 파이 형태로 표현한 그래프이다.
•
박스 플롯 : DataFrame.plot(kind='box')
◦
범주형 데이터의 분포도를 파악하는데 적합하다. 박스 플롯은 5개의 지표를 나타내어 정보를 제공한다.
▪
최대 값 / 3분위 값(75%) / 중간 값(50%) / 1분위 값(25%) / 최소 값
•
커널 밀도 그래프 : DataFrame.plot(kind='kde')
Seaborn 라이브러리
Seaborn 라이브러리는 기존의 Matplotlib 라이브러리의 기능과 스타일을 확장한 라이브러리이다.
그래프 사용법
•
regplot()
◦
서로 다른 2개의 변수 사이의 산점도를 그린 후, 선형회귀분석에 의한 회귀선을 같이 나타냄
▪
fit_reg 옵션은 선형회귀선의 표시 여부이다. (Boolean)
예시•
distplot()
◦
하나의 변수에 대한 데이터의 분포도를 확인할 때 사용한다. 기본적으로 히스토그램과 커널 밀도 함수를 그래프로 출력한다.
▪
hist 옵션은 히스토그램 표시 여부이다. (Boolean)
▪
kde 옵션은 커널 밀도 함수 표시 여부이다. (Boolean)
•
heatmap()
◦
2개의 변수를 각각 X축 Y축에 설정한 후, 데이터를 매트릭스 형태로 분류한다.
▪
annot 옵션은 데이터 값 표시 여부이다. (Boolean)
▪
fmt 옵션은 해당 데이터의 포맷 유형이다.
▪
cbar 옵션은 컬러바 표시 여부이다. (Boolean)
▪
cmap 옵션은 컬러맵이다.
▪
linewidth 옵션은 구분선 옵션이다.
•
stripplot()
◦
이산형 변수의 분포도를 나타내며, 데이터 분산은 고려하지 않는다.
◦
hue 옵션을 사용하여 각 데이터가 특정열의 어떤 값에 속하는지 색깔로 구분해준다.
•
swarmplot()
◦
이산형 변수의 분포도를 나타내며, 데이터 분산은 고려하여 데이터 포인트가 중복되지 않도록 한다.
◦
hue 옵션을 사용하여 각 데이터가 특정열의 어떤 값에 속하는지 색깔로 구분해준다.
•
barplot()
◦
막대그래프를 그리기 위한 함수이다.
▪
hue 옵션을 사용하여 각 데이터가 특정열의 어떤 값에 속하는지 색깔로 구분해준다.
▪
dodge 옵션을 사용하여 여러 데이터를 축 방향으로 분리하지 않고 누적 그래프 출력(겹치게 보임)
•
False로 설정하면 누적 막대로 나타내진다.
•
countplot()
◦
각 범주에 속하는 데이터의 갯수를 확인할 수 있는 그래프를 그리는 함수
▪
x 옵션에 원하는 범주(열) 이름을 작성한다.
•
boxplot()
◦
범주형 데이터의 분포와 지표를 함께 확인할 수 있는 박스 플롯 그래프를 그릴 수 있다.
▪
hue 옵션을 사용하여 각 데이터가 특정열의 어떤 값에 속하는지 색깔로 구분해준다.
•
violinplot()
◦
기존 박스 플롯 그래프와 함께 자주 쓰이는데, 자세한 분포도를 확인하기 위해 더 적합하다.
그래프 모양이 바이올린 모양과 닮아서 violinplot 이라고 부른다.
▪
hue 옵션을 사용하여 각 데이터가 특정열의 어떤 값에 속하는지 색깔로 구분해준다.
•
jointplot()
◦
기본적으로 산점도를 표시(kind 옵션에 따라 변경가능)해주며, X축과 Y축에 각 설정된 변수에 대한 히스토그램도 표시해준다.
▪
kind 옵션 reg : 일반 산점도 그래프 대신 회귀선추가
▪
kind 옵션 hex : 일반 산점도 그래프 대신 육각 산점도 표시
▪
kind 옵션 kde : 일반 산점도 그래프 대신 커널 밀집 그래프 표시
•
Facetgrid()
◦
행과 열에 서로 다른 조건을 적용하여 여러개의 그래프를 생성한다.
import matplotlib.pyplot as plt
import seaborn as sns
...
# col에는 같은 열에 적용될 조건 / 값의 종류에 따라 그래프가 생성된다.
# row에는 같은 행에 적용될 조건 / 값의 종류에 따라 그래프가 생성된다.
g = sns.FacetGrid(data=titanic, col='survived', row='who')
Python
복사
◦
이후 각 서브 플롯(생성되는 그래프)에 적용할 그래프 종류를 선택하여 map() 함수로 전달한다.
import matplotlib.pyplot as plt
import seaborn as sns
...
# col에는 같은 열에 적용될 조건 / 값의 종류에 따라 그래프가 생성된다.
# row에는 같은 행에 적용될 조건 / 값의 종류에 따라 그래프가 생성된다.
g = sns.FacetGrid(data=titanic, col='survived', row='who')
# 그래프 적용하기
# plt.hist를 사용하여 생성되는 서브 그래프를 히스토그램으로 설정
# 생성되는 서브 그래프들의 X축을 'age' 열의 값에 따라 추가 구분
g = g.map(plt.hist, 'age')
Python
복사
파이썬 그래프 예시 사이트
파이썬으로 만들 수 있는 여러 예시를 확인할 수 있다.
Folium 라이브러리
지도위에 데이터를 시각화 할 때 사용되는 유용한 도구이다.
지도 객체 만들기
웹 기반에서 확인할 수 있는 지도 객체를 만들어준다.
•
Map() 함수 사용
◦
location 옵션에 위도 경도를 [위도, 경도] 형태로 입력한다.
◦
zoom_start 옵션으로 지도의 기본 확대 수치를 설정할 수 있다.
import folium
# 서울 지도 만들기
# 위도 & 경도를 [위도, 경도] 형태로 입력한다.
# zoom_start 옵션을 사용하여 기본 줌 상태를 설정할 수 있다.
seoul_map = folium.Map(location=[37.55,126.98], zoom_start=12)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./map.html')
Python
복사
지도 꾸미기
이전에 Map() 함수를 사용하여 생성한 지도를 여러 함수를 통해 스타일 / 정보를 표시하는 마커 등을 추가한다.
•
tiles 옵션 사용
◦
Map() 함수 사용 시 지도의 스타일을 설정할 수 있는 옵션이다.
▪
Stamen Terrain : 산악지대를 강조해서 보여준다.
▪
Stamen Toner : 흑백 스타일의 지도이며, 도로망을 강조해서 보여준다.
▪
...
•
Marker() 함수와 CircleMarker() 함수를 사용하여 지도에 마커 표시
◦
Marker() 함수
지도 위에 마커를 표시하는 함수이다. 마커 설정 후 add_to(map_object) 로 추가해줘야 한다.
▪
위도 & 경도 : 마커가 표시될 위도와 경도를 [위도, 경도] 형태로 입력한다.
▪
popup : 마커를 클릭하였을 때 나타나는 팝업 메세지 설정
import pandas as pd
import folium
...
# 위치정보를 Marker로 표시
# add_to(map_object) 함수로 설정한 마커를 지도에 추가
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.Marker([lat, lng], popup=name).add_to(seoul_map)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./map.html')
Python
복사
◦
CircleMarker() 함수
Marker() 함수와 마찬가지로 지도 위에 마커를 표시하는 함수이다.
마커 설정 후 add_to(map_object) 로 동일하게 추가해줘야 한다.
Marker() 함수 와는 다르게 원형으로 마커가 표시되며 마커의 색깔, 크기등을 마음대로 설정할 수 있는 특징이 있다.
▪
위도 & 경도 : 마커가 표시될 위도와 경도를 [위도, 경도] 형태로 입력한다.
▪
color : 원의 둘레(테두리) 색깔
▪
fill : 원 내부를 채울것인지 (Boolean)
▪
fill_color : 원 내부를 채우는 색깔
▪
fill_opacity : 원의 투명도
▪
popup : 마커를 클릭하였을 때 나타나는 팝업 메세지 설정
import pandas as pd
import folium
...
# 대학교 위치정보를 CircleMarker로 표시
for name, lat, lng in zip(df.index, df.위도, df.경도):
folium.CircleMarker([lat, lng],
radius=10, # 원의 반지름
color='brown', # 원의 둘레 색상
fill=True,
fill_color='coral', # 원을 채우는 색
fill_opacity=0.7, # 투명도
popup=name
).add_to(seoul_map)
# 지도를 HTML 파일로 저장하기
seoul_map.save('./map.html')
Python
복사
•
Choropleth() 함수
색상이나 패턴을 지도위에 표시하여 데이터를 사전 정의된 영역과 관련시켜 시각화 한 지도 유형이다.
보통 특정 구역에 대한 통계를 시각화하기 위해 많이 사용된다.
◦
geo_data : 지도 경계 데이터 파일
◦
data : 표시하려는 데이터
◦
columns : geo_data 와 매핑할 값 (key_on 값과 매핑할 변수, 실제 데이터 값)
▪
(지도 데이터와 매핑할 값, 시각화 하고자하는 변수) 형태의 튜플 값을 넣어줘야 한다.
◦
key_on : 지도 경계 데이터 파일과 매핑할 값 (json 파일에서 값을 얻기 위한 경로)
▪
EX) feature.properties.name
◦
fill_color : Color scheme 값
◦
fill_opacity : 채움 투명도
◦
line_opacity : 테두리 투명도
◦
threshold_scale : 색깔 변경 기준 값 리스트
한글 폰트 설정
그래프 사용 시 한글 부분이 깨져서 출력되는 경우가 있다. 이때는 폰트를 변경해줘야 한다.
환경 설정 파일 수정
•
환경 설정 파일 경로 확인
import matplotlib
print(matplotlib.matplotlib_fname())
------------------------------------------------
/usr/local/lib/python3.6/dist-packages/matplotlib/mpl-data/matplotlibrc
Python
복사
•
나눔 폰트 설치
apt -qq -y install fonts-nanum
Bash
복사
•
환경 설정 파일 수정
font.family 부분 나눔폰트로 수정 후 주석 해제
...
## Note that font.size controls default text sizes. To configure
## special text sizes tick labels, axes, labels, title, etc, see the rc
## settings for axes and ticks. Special text sizes can be defined
## relative to font.size, using the following values: xx-small, x-small,
## small, medium, large, x-large, xx-large, larger, or smaller
font.family: NanumGothic
#font.style: normal
#font.variant: normal
#font.weight: normal
#font.stretch: normal
#font.size: 10.0
...
Bash
복사
•
tensorflow docker 재시작
docker restart tensorflow
Bash
복사
모듈 사용 ( 로컬 컴퓨터 사용 시 권장 )
아래 코드를 실행 코드에 첨부하여 실행 OS에 맞는 환경 폰트가 설정되도록 한다.
import platform
if platform.system() == 'Darwin': # Mac 환경 폰트 설정
plt.rc('font', family='AppleGothic')
elif platform.system() == 'Windows': # Windows 환경 폰트 설정
plt.rc('font', family='Malgun Gothic')
plt.rc('axes', unicode_minus=False) # 마이너스 폰트 설정
Python
복사
DataFrame + Excel
아래 예시처럼 기존 엑셀파일의 내용을 가져와 DataFrame 형태로 수정한 후 반영할 수 있다.
기존 엑셀 파일을 읽을 때는 load_workbook(path) 를 사용하여 새로운 혹은 기존 엑셀파일에 DataFrame내용을 적용할 때는 to_excel() 을 사용한다.
writer.save() 명령어 사용 뒤에는 writer.close() 명령어를 사용하면 안된다.
writer.save() 를 사용하면 자동으로 저장되기 때문에 writer.close() 를 사용하면 에러 발생이나 엑셀파일이 잘못 저장(파일 로드 시 복구 모드 전환 등)이 될 수 있다.
from openpyxl import load_workbook
# excel_data 변수에 기존 엑셀의 정보를 저장한다.
excel_data = load_workbook(EXCEL_PATH)
# 엑셀파일 저장을 위한 접근 변수를 선언합니다
writer = pd.ExcelWriter(EXCEL_PATH, engine='openpyxl')
# excel_data 변수를 사용해 엑셀 파일을 편집합니다.
# 예시로 시트목록 출력
ws = excel_data.sheetnames
print(ws)
# 수정된 엑셀파일을 write 변수를 사용하여 저장합니다.
writer = excel_data
writer.save(EXCEL_PATH)
Python
복사
공식 문서
Tensorflow Docker in vscode
Tensorflow Docker를 사용하여 공부할 때는 가능하면 예시 파일의 이름을 영어로 만들어주는 것이 좋다. read_excel 명령어등으로 파일을 읽을 때 한글 경로를 잘 인식하지 못하기 때문이다.
1.
Tensorflow Docker 실행 (container 이름이 tensorflow 일때 예시)
docker start tensorflow
docker exec tensorflow jupyter notebook --allow-root
Bash
복사
2.
Tensorflow Docker 에서 모듈, 확장 앱 설치
pip3 install jupyter
pip3 install ipykernel
Bash
복사
3.
확장 앱 설치
•
EXTENTIONS → Jupyter 검색 → Install
4.
Shift + Command + P 를 눌러 Jupyter: Specify local or remote Jupyter server for connections 클릭
5.
서버 선택
•
기존에 사용하던 Tensorflow 서버가 있다면 Existing 클릭 후 서버 주소 입력
◦
http://ip:port/?tocken=~~ 형식
•
없다면 Default 클릭
6.
실행을 원하는 python 파일을 선택한 후, 첫 줄에 #%% 를 입력하여 실행 옵션을 확인할 수 있다.
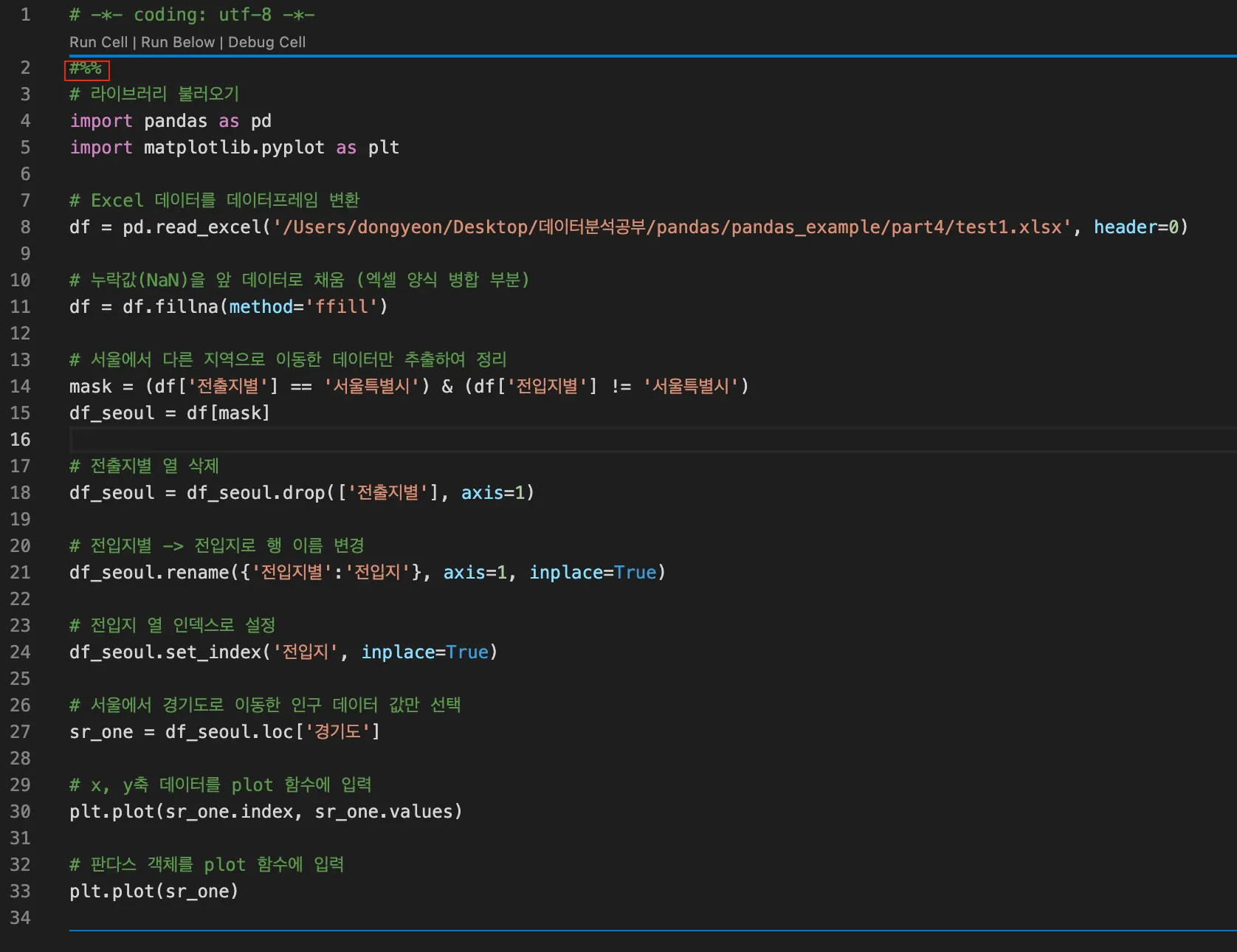
7.
Run cell 을 입력하여 실행이 가능하다.
docker tensorflow 사용 시 주의사항
docker 에서 동일한 포트(8888) 사용 시 로컬에 설치된 tensorflow 서버와 충돌하여 정상적으로 작동하지 않는 경우가 발생하니 잘 확인해야한다.
그래서 기본적으로 연결할 tensorflow 서버를 설정해주는 것이 좋다. 아래와 같이 설정하면 기본적으로 원격 서버 연결로 시도하기 때문에 로컬 서버와 충돌할 일이 없다.
1.
Junyper의 Extention Settings 에 접속하여 검색창에 connect 를 입력
2.
Jupyter: Jupyter Server Type 을 remote 로 설정
Jupyter 패스워드 접속 설정
docker에서 Jupyter를 올린 후 간편한 원격 접속을 위해 토큰 입력 대신 패스워드 인증 방식으로 변경하는법
•
Jupyter에서 프로파일을 생성해준다.
jupyter notebook --generate-config
Bash
복사
•
ipython과 해시를 이용한 패스워드 생성
root@d99491ce3708:/# ipython
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.16.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from IPython.lib import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'sha1:24ae8778cfa5:686065fe6e4de74581e9da43fc62572d154c94e9'
In [3]: exit
Python
복사
•
1번에서 생성한 프로파일을 수정한다. 기본적으로 전부 주석 내용이라서 맨 밑 / 맨 위에 작성해주면 된다.
...
c = get_config()
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.open_browser = False
# 기본적으로 설정을 하지 않으면 8888번에서 동작하기 때문에, 로컬에서 추가적으로 Jupyter를
# 동작시킨다면 포트번호가 겹치지 않도록 잘 확인해야 한다.
c.NotebookApp.port = 8888
c.NotebookApp.password = 'sha1:24ae8778cfa5:686065fe6e4de74581e9da43fc62572d154c94e9'
...
Python
복사
•
Jupyter notebook 을 실행한다.
--allow-root 옵션은 jupyter notebook 명령어를 루트 계정에서 실행할 때 사용한다.
보통 docker에서 쉘에 접속하면 기본적으로 root 계정이라 자주 사용된다.
jupyter notebook --allow-root
Bash
복사
•
http://ip:port 로 접속하여 패스워드를 입력하면 진행이 가능하다.