ChatGPT란?

많은 분들이 ChatGPT와 GPT-3(GPT)를 헷갈려하십니다. 몇몇 분들은 ChatGPT와 GPT-3(GPT)를 동일하다고 하시는 경우도 있으신데, 둘은 엄연히 다른 개념입니다.
ChatGPT는 GPT라는 딥러닝을 사용한 인공지능 모델을 사용하여 만들어진 대화형 모델입니다.
여기서 사용되는 GPT를 OpenAI사에서 제작하였으며, [ GPT-2 → GPT-3 → GPT-3.5 → GPT-4 ] 순서로 새로운 모델을 계속하여 출시 중입니다.
GPT란?
Generative Pre-trained Transformer의 약자로 GPT라고 부릅니다.
여기서 Pre-trained이란, 단어 그대로 미리 훈련된 → “사전훈련” 이라고 부릅니다.
GPT는 어마무시한 양의 Parameter와 사전훈련을 사용한 결과물로, GPT-3는 1750억개의 Parameter를 사용했다고 합니다.
Parameter란?
여기서 Parameter란 모델 내부에서 정해지는 변수를 의미하는데, 개발 시 사용되는 Parameter와 비슷하다고 할 수 있습니다.
예시로 우리가 인사를 하면 답장을 하는 모델을 만든다고 가정해봅시다. 여기서 홍길동 이라는 이름을 다른 이름으로 변경할 수 있습니다.
[ INPUT ]
안녕? 나는 홍길동이야 :)
[ OUTPUT ]
안녕하세요. 홍길동님! 좋은 하루 보내세요 :)
Plain Text
복사
이처럼 훈련을 위해 모델 내부에서 정해지는 변수를 Parameter라고 합니다.
ChatGPT의 원리
그렇다면 ChatGPT는 GPT를 어떻게 사용하여 만들어진 걸까요?
ChatGPT에 대한 설명을 보면, 아래와 같은 내용이 작성되어 있습니다.
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
InstructGPT와 동일한 방법을 사용하지만 데이터 수집 설정이 약간 다른 RLHF(Reinforcement Learning from Human Feedback)를 사용하여 이 모델을 교육했습니다.
새로운 키워드인 InstructGPT, RLHF를 확인할 수 있습니다.
또한 ChatGPT는 InstructGPT라는 또 다른 모델과 동일한 방식으로 학습된 모델임을 알 수 있습니다.
RLHF란?
상세 내용은 OpenAI의 공식 페이지를 참고해주세요!
[ 공식 페이지 ] : https://openai.com/research/learning-from-human-preferences
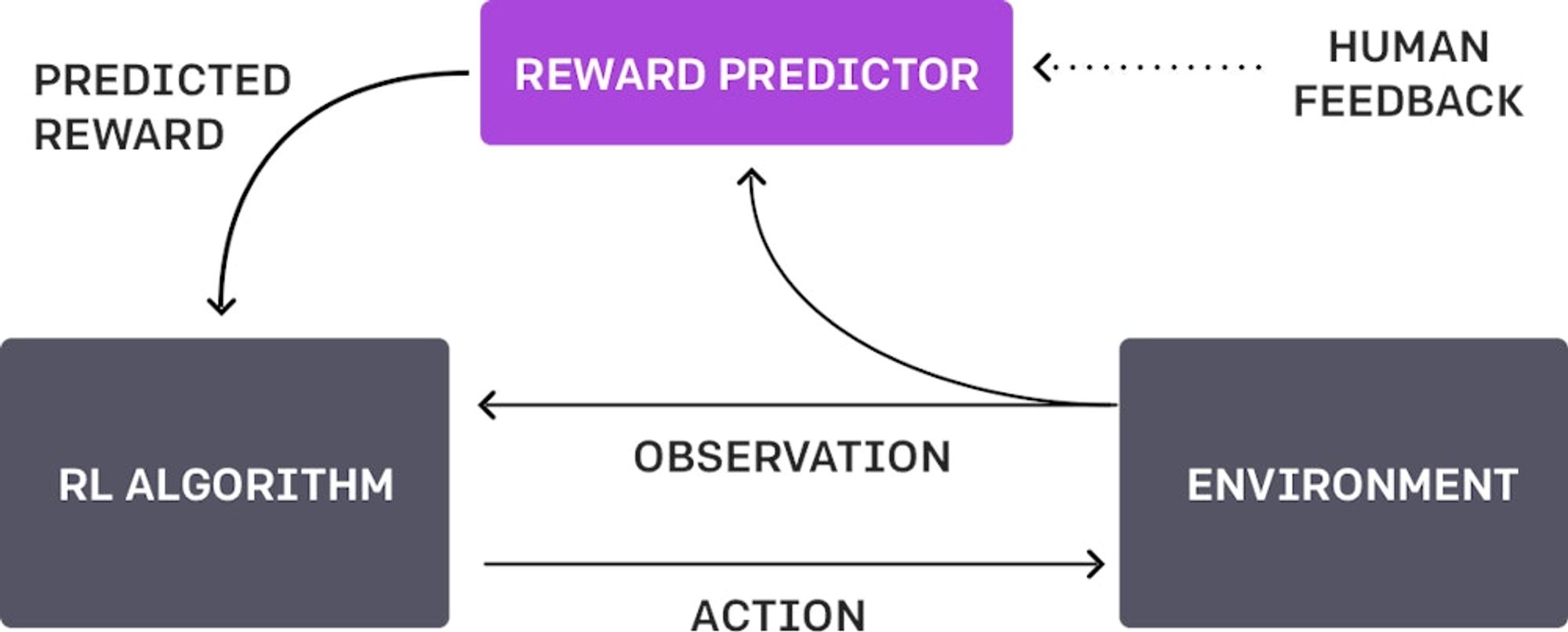
Reinforcement Learning with Human Feedback의 약자로, 해석하면 인간의 피드백을 통한 강화 학습 방식을 의미합니다.
대량의 데이터를 주입하여 학습한 기존의 방식과 다르게 Output에 대한 피드백이 진행되기 때문에, 많지 않은 기존의 데이터 셋으로도 학습이 가능합니다.
학습을 반복할수록 초기의 수립된 목표에 가까운 Output을 낼 수 있도록 계속하여 학습할 수 있습니다.
InstructGPT란?
We’ve trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. These InstructGPT models, which are trained with humans in the loop, are now deployed as the default language models on our API.
우리는 우리의 alignment 연구를 통해 개발된 기술을 사용하여 GPT-3보다 훨씬 더 사용자 의도를 따르는 언어 모델을 훈련시키고 동시에 진실성이 더 높고 유해성이 적은 모델로 만들었습니다. 이를 위해 인간을 포함한 방식으로 훈련된 InstructGPT 모델을 사용합니다. 이러한 InstructGPT 모델은 이제 우리 API의 기본 언어 모델로 배포되었습니다.
간단하게 요약하면 기존 GPT-3는 많은 Parameter를 통해 자연어 처리에는 뛰어난 효과를 보였습니다.
하지만 사용자의 의도에 맞는 결과를 잘 주지 못하였고, 이를 위해 사용자 의도에 더 잘 따르는 새로운 모델을 만들었습니다.
GPT-3 vs InstructGPT 답변 결과 비교간단한 예시를 들겠습니다. ChatGPT는 InstructGPT와 동일한 방식으로 학습이 진행되었습니다.
그래서 아래와 같이 사용자의 의도를 명확하게 설정한다면, 이에 맞는 답변을 잘 반환해줍니다.
ChatGPT의 답변 예시
이와 같이, 기존 GPT-3와 달리 사용자의 의도를 잘 따르는 모델이 되도록 초점을 맞춘 모델이라고 할 수 있습니다.
또한, 성능적으로 매우 뛰어난 결과를 보여주어서 GPT-3 API를 사용할 때 실제 GPT-3 대신 InstructGPT를 사용하도록 설정(text-davinci-001)되어 있습니다.
InstructGPT의 학습 방식
아래 이미지는 공식 사이트에 작성된 InstructGPT의 학습 방식을 그려놓은 이미지입니다.
Step 별로 확인해보겠습니다.

Step1 - Collect demonstration data and train a supervised policy
1차적으로 Prompt와 이에 맞는 결과물이 존재하는 데이터셋을 사용하여 라벨러(사람)가 데이터셋을 엄선하여 결정 후 GPT-3에 “Fine-Tune” 을 진행하여 학습된 모델을 얻습니다.
이렇게 얻어진 모델을 SFT(Supervised Fine-Tuning) 모델이라고 합니다.
이 모델은 차후 강화 학습(RL)에서 사용됩니다.
Prompt란? Fine-Tune이란?Step2 - Collect comparison data, and train a reward model
GPT-3 모델을 사용하여 Prompt를 이용, 다수의 결과를 얻어냅니다. 이 결과들을 라벨러(사람)이 확인하여 답변의 선호도 순위를 설정합니다.
이렇게 설정된 답변의 선호도를 이용하여 Reward Model(RM), 보상 모델을 학습시킵니다.
이 모델은 차후 강화 학습(RL)의 중요한 요소로 사용됩니다.
Step3 - Optimize a policy against the reward model using reinforcement learning
마지막으로, 아래 순서를 반복하여 Step1에서 “Fine-Tune” 된 SFT를 계속해서 강화학습(RL)을 시켜줍니다.
1.
새로운 Prompt를 입력합니다.
2.
Step2의 보상 모델(RM)은 SFT의 답변을 계산하여 reward 값()을 얻습니다.
3.
4.
이후 더욱 최적화된 학습 정책을 통해 새로운 Prompt를 또 다시 입력하여 1~3 과정을 반복합니다.
ChatGPT vs InstructGPT
위 내용에서 ChatGPT와 InstructGPT의 학습 방식은 동일하다고 했는데, 그럼 어떤차이가 있는 걸까요?
학습 방식 | ChatGPT | InstructGPT |
학습 데이터 | 일상 대화, 소셜 미디어 글 | 학습 가이드, 문서 |
목적 | 대화 생성 | 지시 및 설명 생성 |
문맥 처리 | 대화문맥 전체 이해 | 지시/설명문맥 일부만 이해 |
Fine-Tuning | Yes (대화 데이터) | Yes (직무/분야 데이터) |
ChatGPT는 이름 그대로 ChatGPT, GPT를 기반으로 만들어진 대화형 모델입니다.
InstructGPT는 이름 그대로 InstructGPT, GPT를 기반으로 만들어진 지시에 대한 답변을 위한 모델입니다.
즉, RLHF 학습에 사용된 초기 데이터 셋이나 Fine-Tuning에 사용된 데이터가 차이가 있을 것이고 이에 따라 목적과 부르는 명칭이 다릅니다.
정리
ChatGPT, InstructGPT는 모두 GPT 모델을 사용하여 만든 언어 모델입니다.
InstructGPT는 RLHF 학습법과 PPO 알고리즘을 사용하여 사용자가 원하는 답에 가까운 결과를 주도록 학습된 대화형 모델입니다.
ChatGPT는 InstructGPT와 동일한 방식으로 학습된 대화형 모델이지만, 학습에 사용된 데이터가 다릅니다.