
아래 내용은 남궁성 저자님의 “자바의 정석 기초편" 유튜브 강의를 들으며 개인적으로 정리한 내용입니다!
실제 강의 수강을 강력히 권장드리며, “자바의 정석" 책을 구매하시는 것도 추천드립니다.
→ https://www.youtube.com/watch?v=D7XvKPQsEa0&list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp
자바란? / 자바의 특징
자바란?
프로그래밍 언어 중 하나로, 컴퓨터 프로그램 제작에 사용된다.
실행환경(JRE) + 개발도구(JDK) + 라이브러리(API)로 구성된다.
자바의 특징
1.
객체지향 언어이다.
→ C++, Python, Js와 같이 객체지향 언어이다.
2.
자동으로 메모리를 관리해준다.
→ Python과 같이 가비지 컬렉터(GC)가 존재하여, 프로그램이 동적으로 할당한 메모리 영역에 대해 별도로 관리하기 때문에 사용자가 별도로 관리하지 않아도 된다.
3.
멀티 쓰레드를 지원한다.
4.
라이브러리가 풍부하여 다양한 기능의 개발이 가능하다.
5.
운영체제에 독립적이다.
→ JVM이라는 자바 가상 머신으로 Java 애플리케이션을 동작시키기 때문이다.
→ 따라서, 각 OS에 맞는 별도의 애플리케이션으로 만들어야하는 다른 언어와 달리 자바는 각 OS의 JVM만 설치한다면 운영체제에 제한받지 않고 실행이 가능하다.
JVM 구조와 자바 프로그램 동작 순서
아주 잘 설명해주신 글이 있어 이미지와 내용을 참고하였습니다!
→ https://steady-snail.tistory.com/67
자바 프로그램 동작 순서
•
전체적인 동작 방식
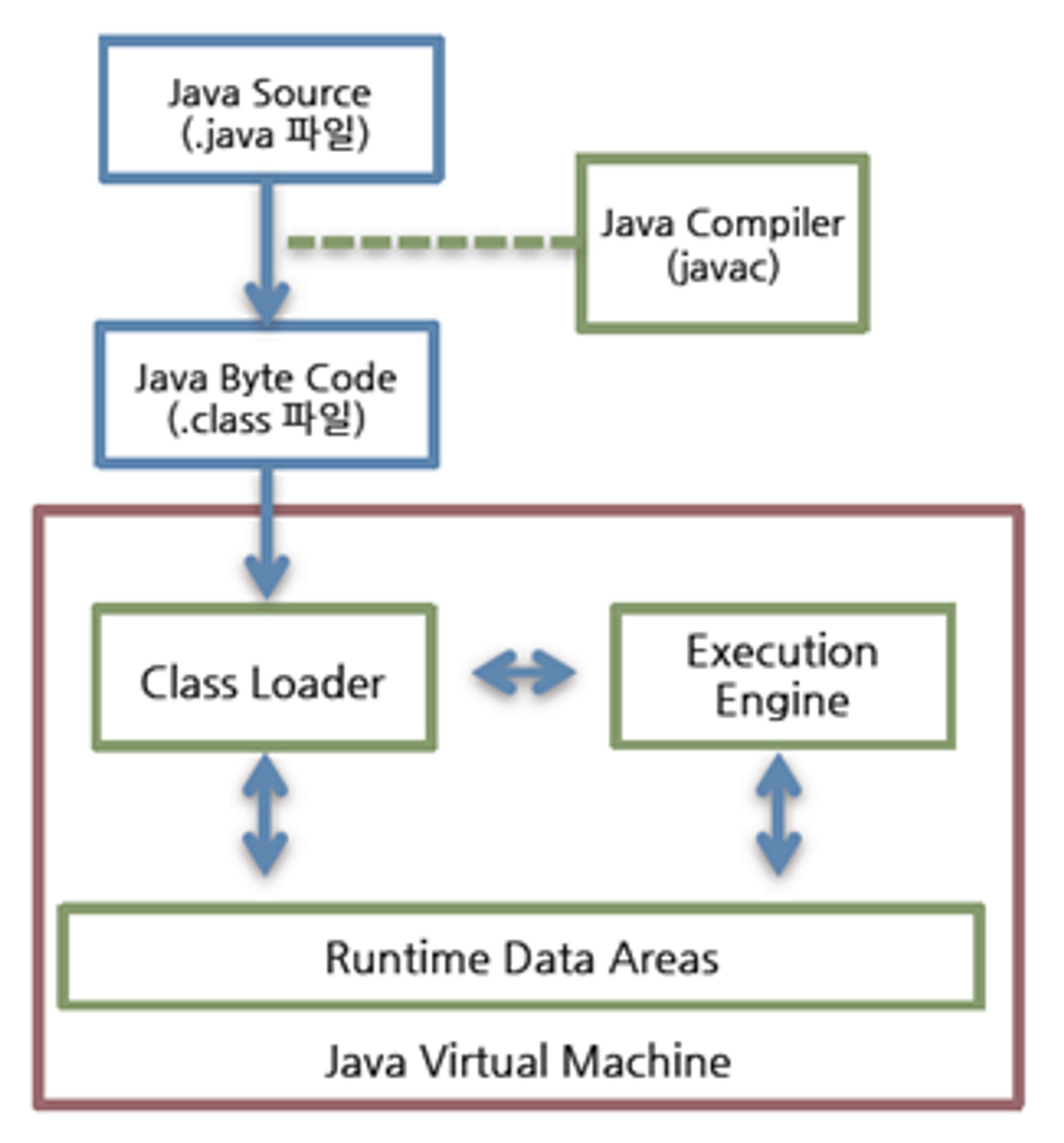
1.
JAVA Compiler가 .java 파일을 .class 확장자인 바이트코드로 컴파일한다.
2.
컴파일된 바이트코드를 JVM의 클래스 로더에 전달한다.
3.
클래스로더는 동적로딩을 통해 필요한 클래스들을 로딩 및 링크하여 JVM의 메서드 영역에 올린다.
4.
실행엔진이 JVM의 메서드 영역에 올라온 바이트 코드를 명령어 단위로 하나씩 가져와 실행한다.
JVM 구조
JVM은 클래스 로더(Class Loader), 런타임 데이터 영역 (Runtime Data Area), 실행 엔진(Execution Engin)으로 구조가 나뉘어져있다.
클래스로더(Class Loader) 정의와 특징
JRE의 일부로서 자바 소스코드가 컴파일 된 바이트코드(.class)를 읽어 들여 JVM의 메서드 영역에 로딩하는 역할을 수행한다.
클래스로더의 특징은 아래 5가지로 설명할 수 있다.
계층 구조
위임 모델
가시성 제한
언로드(Unload) 불가
네임스페이스
클래스로더(Class Loader) 과정
클래스로더 과정은 아래 5단계 진행된다. 이중 2~4단계는 링킹(Linking)과정으로 부른다.
1.
로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드한다.
2.
검증 : 읽어들인 클래스의 바이너리 데이터(.class)가 유효한지 확인한다.
3.
준비 : 클래스에 정의된 필드, 메서드, 인터페이스를 나타내는 데이터 구조 등에서 필요한 메모리 영역을 할당한다.
4.
분석
심볼릭 레퍼런스란?
참고하는 클래스의 특정 메모리 주소를 참조 관계로 구성한 것이 아니라 참조 대상의 이름만 지칭한 것.
•
이 과정은 사용되는 환경에 따라 동작 유무가 정해진다.
•
클래스 파일은 JVM이 프로그램을 실행 시 필요한 API를 Link할 수 있도록 심볼릭 레퍼런스를 가진다.
•
심볼릭 메모리 레퍼런스가 메소드 영역에 있는 실제 힙 메모리 영역에 있는 인스턴스에 대한 레퍼런스로 교체된다.
◦
즉 실제 인스턴스와 연결해주는 것
5.
초기화 : 클래스 변수들을 적절한 값으로 초기화한다. (static 필드를 설정된 값으로 초기화 등)
런타임 데이터 영역 (Runtime Data Area)
JVM이 OS위에서 실행되며 할당받는 메모리 영역이다. 이 영역은 크게 6가지로 나눌 수 있다.
자바는 멀티스레드를 지원하기 때문에, 멀티스레드를 사용할 경우 할당받은 메모리 영역 중 일부는 여러 스레드가 공유한다.
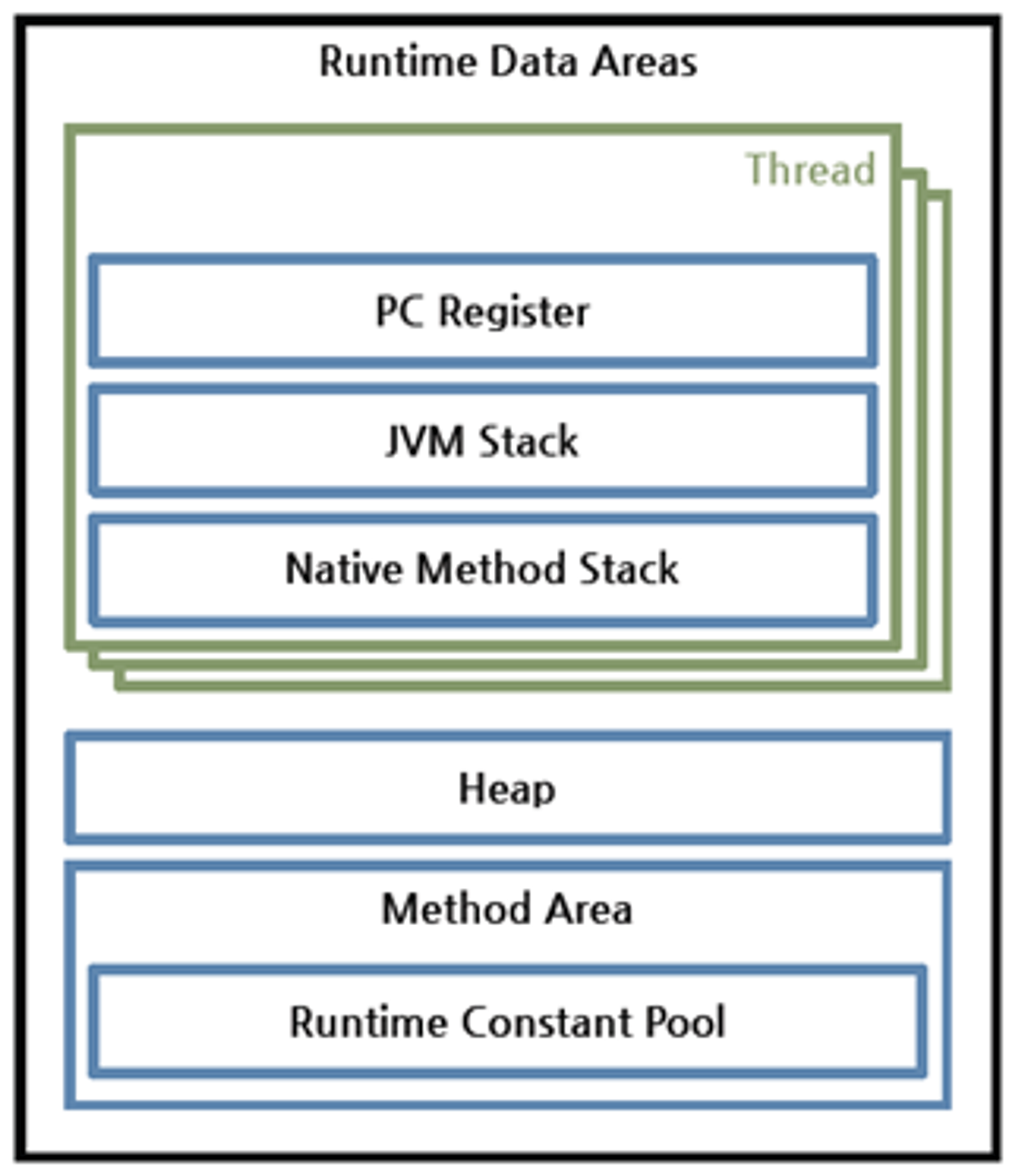
PC 레지스터 | 각 스레드가 실행할 명령에 대한 기록을 저장한다. (실행 주소 등) | 각 스레드마다 생성 |
JVM 스택 | • 메소드의 상태 정보를 저장하는 스택 프레임(Stack Frame)이라는 구조체를 저장
• 메서드가 수행될 때마다 하나의 스택 프레임을 추가(push), 메서드 종료 시 스택 프레임이 제거(pop)
• 각 스레드가 할당받은 스택 사이즈를 넘게 되면 StackOverflowError 발생
• 스택 사이즈를 동적 확장 시 혹은 새로운 스레드 생성 시 할당할 메모리가 부족하면 OutOfMemoryError 발생 | 각 스레드마다 생성 |
네이티브 메서드 스택 | JAVA외 언어로 작성된 네이티브 코드를 위한 스택이다. 작성된 언어에 맞는 스택이 생성된다. | 각 스레드마다 생성 |
힙 | 인스턴스나 객체를 저장하는 공간으로 자바의 가장 큰 특징 중 하나인 가비지 컬렉션이 관리하는 영역이다. | 모든 스레드 공유 |
메서드 영역 | JVM 시작 시 생성되며 JVM이 읽어 들인 각각의 클래스, 인터페이스에 대한 런타임 상수 풀, 필드/메서드 정보, Static 변수 등을 보관한다. | 모든 스레드 공유 |
스택 프레임(Stack Frame) 구성
런타임 상수 풀(Runtime Constant Pool)이란?
실행 엔진(Execution Engin)
클래스 로더를 통해 런타임 데이터 영역에 배치된 바이트 코드를 명령어 단위로 읽어 실행하는 역할이다.
CPU가 기계 명령어를 하나씩 실행하는 것과 비슷하다.
이때 읽어오는 명령어는 1바이트 크기의 OpCode와 추가 피연산자로 이루어져 있다.
실행엔진은 OpCode를 가져와 피연산자와 작업 수행 후 → 다음 OpCode를 수행한다.
하지만, 자바 바이트코드는 기계가 바로 수행할 수 있는 언어가 아닌 인간이 보기 편한 형태로 기술되어 있다.
즉, JVM에서 기계가 실행할 수 있는 형태로 변경할 필요가 있으며 두 가지 방식을 사용한다.
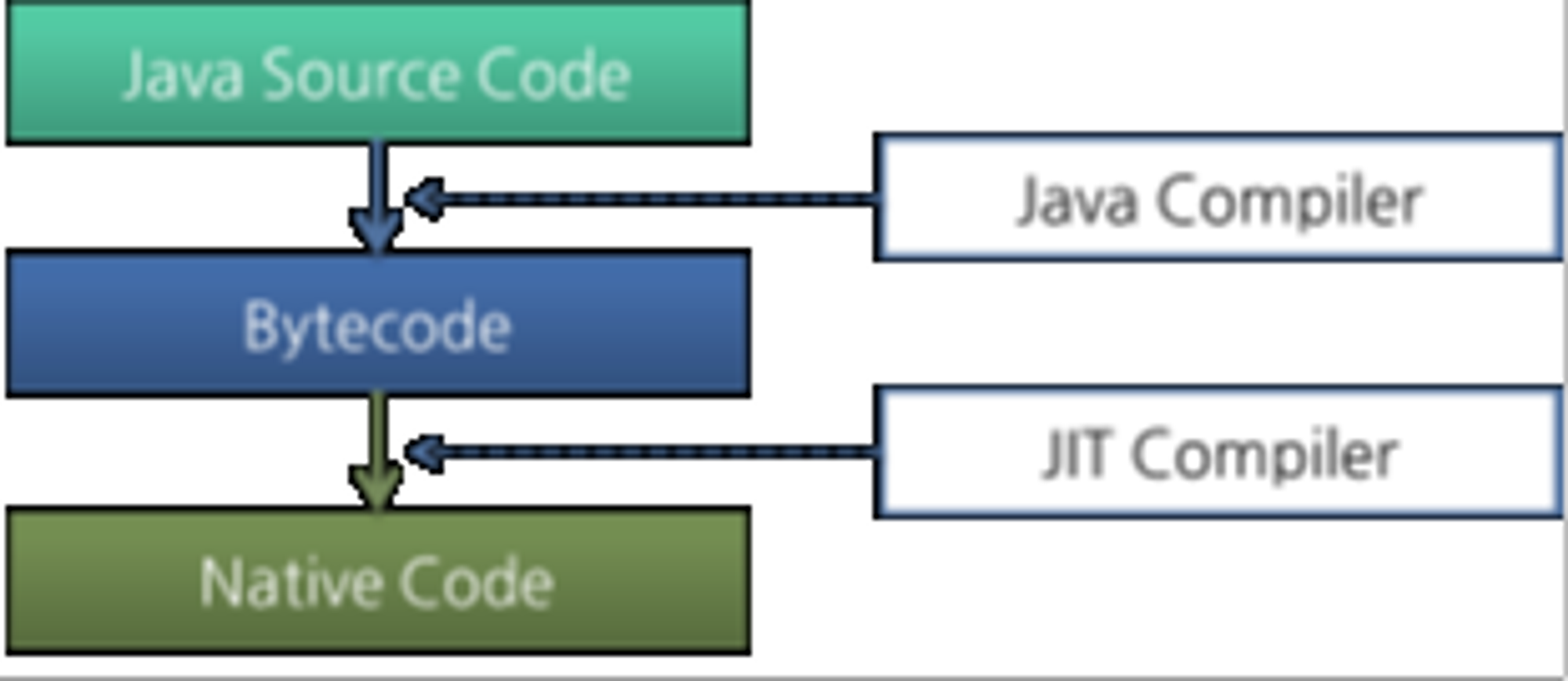
인터프리터 방식
JIT(Just-In-Time) 컴파일러 방식
JIT 컴파일 방식은 인터프리터보다 훨씬 오래걸린다. → 인터프리터 방식으로 한번 실행 후, 네이티브로 컴파일까지 하기 때문이다.
즉, 한 번만 실행되는 코드라면 굳이 이 방식으로 컴파일하지 않고 인터프리팅만 해서 빠르게 끝내는게 유리하다.
하지만 해당 메서드가 자주 수행된다면, 네이티브로 컴파일하여 사용하는게 유리하다.
상황에 따라 유리한 컴파일 방식이 다르기 때문에, JVM도 내부적으로 메서드의 수행 빈도를 체크 후 일정 기준을 넘을때만 네이티브로 컴파일한다.
입출력 / 변수
입력
화면을 통한 입력
Scanner 클래스를 이용하여 화면으로부터 데이터를 입력받는다. Scanner 클래스는 객체를 별도로 생성해야 사용할 수 있다.
// import
import java.util.*;
// 객체 생성
Scanner scanner = new Scanner(System.in);
// 숫자를 하나로 화면에서 입력받아 저장
int num = scanner.nextInt();
// 한 라인 단위로 입력을 받는다.
String input = scanner.nextLine();
Java
복사
커맨드 라인을 통한 인자로 데이터 입력
프로그램 실행 시, 메인의 args 라는 배열에 커맨드 라인으로 입력한 데이터 값이 들어있다.
이때 기본적으로 사용되는 args라는 이름은 arguments의 약자이다. 즉 변경해도 문제는 없다.
java Hello 1 "HELLO" "WORLD" 100
Bash
복사
public class Hello {
public static void main(String[] args) {
for (int i=0;i<args.length;i++){
System.out.println(args[i]);
}
}
}
// 결과
// 1
// HELLO
// WORLD
// 100
Java
복사
출력
•
System.out.print(value) : 값을 출력 후 줄바꿈을 하지 않는다.
•
System.out.println(value) : 값을 출력 후 줄바꿈을 한다.
•
System.out.printf(format, args) : 기존의 print, println이 형식화된 출력을 하지 못하기 때문에 사용된다.
◦
print, println은 출력할 소수점 자리수를 지정할 수 없다.
◦
print, println은 정수를 10진수로만 출력한다. 8진수와 16진수를 출력할 수 없다.
◦
printf는 줄바꿈을 자동으로 하지 않는다.
지시자
printf에서 값을 원하는 형식으로 출력하기 위해 사용된다.
지시자 | 설명 | 타입 |
%b | boolean 형식으로 출력 | 논리 |
%d | 10진수 형식으로 출력 | 정수 |
%o | 8진수 형식으로 출력
%#o을 사용하면 접두사가 붙어 결과가 출력 | 정수 |
%x, %X | 16진수 정수 형식으로 출력
%#x/%#X을 사용하면 접두사가 붙어 결과가 출력 | 정수 |
%f | 부동 소수점의 형식으로 출력
- 이때 소수점아래 6자리를 출력한다.
- float의 정밀도는 7자리까지이기 때문에 소수점 아래 4자리 이후는 의미없는 숫자일 수 있다. | 실수 |
%e, %E | 지수 표현식의 형식으로 출력
- 0이 많이 들어간 소수에서 사용하면 1.234568e+02와 같이 출력 | 실수 |
%c | 문자(char)로 출력 | 문자 |
%s | 문자열(String)으로 출력 | 문자 |
%n | 개행문자를 출력 → OS에 구애받지 않음
따라서 printf를 쓸 때 %n를 사용하여 개행하는 것을 권장 | - |
정수타입의 지시자 사용법
실수타입의 지시자 사용법
문자 타입의 지시자 사용법
변수(variable)
하나의 값을 저장할 수 있는 메모리 공간을 의미한다. [변수타입] [변수이름]; 형식으로 정의한다.
파이썬과 달리 자바는 변수 타입을 같이 정의해줘야 하며 설정한 타입과 다른 타입의 값으로 설정하면 에러가 발생한다.
예시로, int count; 와 같이 정의하면 정수(int)타입의 변수 count를 선언한다.
만약 여러 변수 선언 시, 모두 타입이 같다면 아래와 같이 동시 선언이 가능하다.
int x = 0; // x 선언 후 0으로 초기화
int y = 5; // y 선언 후 5로 초기화
int w = 0, k = 1; // w, k의 선언과 초기화 작업을 한번에 진행 (같은 자료형을 가진 여러변수 한번에 선언 가능)
Java
복사
상수(constant)
변수는 저장된 값을 계속 바꿀 수 있지만, 상수는 처음 한 번만 값의 저장이 가능하다. 즉 값의 변경이 불가능하다.
final 이라는 키워드를 추가하여 선언한다.
final int NUMBER = 100; // NUMBER 라는 상수를 선언
NUMBER = 500; // NUMBER 상수의 변경을 시도 -> 에러 발생
Java
복사
리터럴(literal)
그 자체로 값을 의미하는 것이다. 의미만으로 헷갈리니 예시로 확인해보자
// 여기서 int, char, String은 변수 타입이다.
// 여기서 count, ch, str은 변수이다.
// 여기서 10, 'A', "abc"는 자체로 값을 의미하는 리터럴이다.
int count = 10;
char ch = 'A';
String str = "abc";
Java
복사
리터럴의 접두사와 접미사
주의사항
데이터 타입
타입에는 기본형 타입과 참조형 타입이 존재한다. 기본형 타입은 실제 값을 저장하는 8개의 타입이다.
각 타입의 표현범위( → 타입의 비트 수 / 1byte = 8bit)
배열의 타입 / 객체의 클래스을 확인하는 방법
기본형 타입
•
문자 : char
•
숫자
◦
정수 : byte(1byte), short(2byte), int(4byte), long(8byte)
◦
실수 : float(4byte), double(8byte)
•
논리 : boolean
이때 숫자형(정수, 실수) 타입은 타입.MAX_VALUE / 타입.MIN_VALUE 로 해당 타입의 가장 큰 값과 가장 작은 값을 얻을 수 있다.
System.out.println(Byte.MAX_VALUE); // 127
System.out.println(Byte.MIN_VALUE); // -128
System.out.println(Short.MAX_VALUE); // 32767
System.out.println(Short.MIN_VALUE); // -32768
System.out.println(Integer.MAX_VALUE); // 2147483647
System.out.println(Integer.MIN_VALUE); // -2147483648
System.out.println(Long.MAX_VALUE); // 9223372036854775807
System.out.println(Long.MIN_VALUE); // -9223372036854775808
System.out.println(Float.MAX_VALUE); // 3.4028235E38
System.out.println(Float.MIN_VALUE); // 1.4E-45
System.out.println(Double.MAX_VALUE); // 1.7976931348623157E308
System.out.println(Double.MIN_VALUE); // 4.9E-324
Java
복사
또한 파이썬의 float(’inf’) / float(’-inf’) 처럼 양의 무한대 / 음의 무한대를 구현할 수 있다.
최대 값이나 최소 값을 담는 변수의 초기값으로 유용하게 사용할 수 있다.
System.out.println(Float.POSITIVE_INFINITY); // Infinity
System.out.println(Float.NEGATIVE_INFINITY); // -Infinity
System.out.println(Double.POSITIVE_INFINITY); // Infinity
System.out.println(Double.NEGATIVE_INFINITY); // -Infinity
Java
복사
참조형 타입
참조형은 기본형이 아닌 타입을 말하며 정해진 수가 없다. 또한 실제 값을 저장하지 않고 값이 저장된 메모리 주소를 저장(4byte/8byte)한다는 차이점이 있다.
클래스를 만들어 사용하면 새로운 참조형을 추가한다고 말할 수 있다.
•
참조형 타입 종류 : 객체(Object), 배열(Array), 날짜(Date), 문자열(String) 등등
String 클래스
char[] 와 메서드(기능)을 결합한 것이라고 할 수 있으며, 내용 변경이 불가능한 대표적인 특징을 가지고 있다.
•
String 클래스의 주요 메서드
메서드 | 반환 타입 | 설명 |
String.charAt(int idx) | char | 문자열에서 idx 인덱스에 존재하는 문자를 반환한다. |
String.length() | int | 문자열의 길이를 반환한다. |
String.substring(int from, int to) | String | 문자열에서 from ≤ idx < to 범위의 문자열을 반환한다. |
String.equals(Object obj) | boolean | 두 객체의 문자열 내용이 같은지 확인한다.
맞으면 true, 다르면 false 반환 |
String.toCharArray() | char[] | 문자열을 문자배열(char[])로 변환하여 반환한다.
String 객체는 str[1] 처럼 참조할 수 없다. |
형변환
String → int
int → String
문자, 문자열
문자를 정의할때는 ‘’ 를 이용하여, 문자열을 정의할 때는 “” 을 이용해 정의한다.
이때 여러 주의 사항이 있다.
1.
char ch = ‘AB’;와 같이 문자를 저장하는 char 타입의 변수에는 문자열을 저장할 수 없다.
2.
String 변수에는 빈 문자열(empty String) 값으로 초기화가 가능하지만, Char 타입은 불가능하다.
3.
String test = “A” + “B”; 와 같이 + 를 이용하여 문자열 결합이 가능하다.
4.
문자열 + any type = 문자열 을 이용하여 빈 문자열(empty String)과 숫자 리터널을 더하면 문자열 변환이 가능하다.
•
왼쪽에서 오른쪽으로 연산이 진행되기 때문에, 순서에 유의해야한다.
◦
“” + 7 + 7 → “77”
◦
7 + 7 + “” → “14”
5.
문자열 비교 시, == / != 대신에 str1.equals(str2) 로 비교해야한다.
왜냐하면 == / != 연산자는 두 대상의 주소값을 비교한다.
하지만 equals 메소드는 두 대상의 값 그 자체를 비교하기 때문이다.
따라서, == / != 연산자는 new String(str) 형태로 선언된 두 변수를 비교 시 정확한 비교가 안될 수 있다.
보통 일반적으로 문자열을 비교할 때는 값의 비교의 목적이 대부분이기 때문에, equals() 메서드를 사용하는게 좋다.
연산자
종류 | 연산자 |
단항 연산자 | ++, --, +, -, ~, !, (type) |
산술 연산자 | *, /, %, +, -, <<, >> |
비교 연산자 | <, >, <=. >=, instanceof, ==, != |
논리 연산자 | &, ^, |, &&, || |
삼항 연산자 | [조건] ? [참일 때] : [거짓일 때] |
대입 연산자 | =, +=, -=, *=, /=, %=, <<= , >>= , &=, ^=, |= |
증감연산자
증감연산자 ++, -- 는 전위형과 후위형으로 나뉜다.
•
전위형 → 값이 참조되기 전 증가시킨다.
•
후위형 → 값이 참조된 후에 증가시킨다.
int i = 10;
int j = 10;
int k;
// 전위형
k = ++i;
// 11
System.out.println(k);
// 후위형
k = j++;
//10
System.out.println(k);
Java
복사
형변환 연산자
다른 타입으로 변환하기 위해 사용되는 연산자이다. (type)var 형식으로 사용한다.
간단히 예시로 확인해보자.
변환 | 예시 | 결과 | 과정 |
int → char | (char)65 | ‘A’ | 아스키코드 65번인 ‘A’로 변환 |
char → int | (int)’A’ | 65 | ‘A’는 아스키코드 65번이기 때문에 65 반환 |
float → int | (int)1.6f | 1 | int형은 소수점 자리를 가지지 않기 때문에 정수 부분만 반환
단, 이때 반올림 되는게 아니고 그냥 소수점을 다 버린다. |
int → float | (float)10 | 10.0f | float형은 소수점을 가지기 때문에 10.0 반환 |
사칙 연산과 산술변환
서로 다른 두 타입을 연산할 때, 더 범위가 큰 타입으로 결과가 나타난다.
int a = 100;
float b = 4.0f;
// 25.0
// float타입이 int형보다 더 큰 범위의 타입이기 때문에 값 손실을 막기 위해 float으로 결과 출력
System.out.print(a / b);
Java
복사
위 같은 이유 등으로 연산 전에 피연산자의 타입을 일치시키는 것을 산술변환이라고 한다.
이때 아래 규칙을 따른다.
1.
두 피연산자의 타입을 두 타입 중 큰 타입으로 일치시킨다.
•
int + long → int + int → int
•
float + int → float + float → float
•
float + double → double + double → double
•
…
2.
피연산자의 타입이 int보다 작은 타입이면 int로 반환된다.
왜냐하면 피연산자 중 큰 타입이 결과를 담지 못하는 경우가 존재하기 때문이다.
( → ERROR
•
byte + short → int + int → int
•
char + short → int + int → int
char + char → int + int → int
int + int → int + int → int
그 외 여러가지
반올림
실수를 반올림한 값을 반환하기 위해 사용한다. 이때 Math.round(실수) 를 사용한다.
Math.round(실수) 함수는 소수 첫번째 자리를 기준으로 반올림하여 정수를 반환한다.
double n = 3.5;
// 4(int)
print(Math.round(n));
Java
복사
이때 아쉬운점이 원하는 자리수에서 반올림을 바로 하지 못한다는 것이다.
3.1452 를 소수 3번째 자리에서 반올림 → 3.15 와 같은 과정을 바로 못하는 것이다.
이럴때는 초기값을 곱해 증가시켜 반올림을 원하는 자리수를 소수 첫번째 자리로 이동 후 → Math.round()를 사용해 반올림 후 → 다시 나눠주는 방법을 사용한다.
Math.round() 결과가 int형이기 때문에, 다시 나눠줄때는 실수형으로 나눠줘야한다.
double n = 3.1452;
// 소수 3번째 자리에서 반올림한 결과
// 3.15
System.out.println(Math.round(n * 100)/100.0);
Java
복사
임의의 숫자 만들기
Math.random()을 사용하여 원하는 범위의 숫자를 얻을 수 있다.
하지만 Math.random() 결과값은 0 ≤ Math.random() < 1 범위의 double 값이다.
•
원하는 범위 설정
예를 들어 0 ≤ result < 1의 범위를 0 ≤ result < 10의 범위로 변경하는 방법이다.
결과 값에 원하는 범위만큼 곱해주면 된다.
// 0 <= result < 10
System.out.println(Math.random() * 10);
// 0 <= result < 20
System.out.println(Math.random() * 20);
Java
복사
•
시작 범위를 변경
예를 들어 0 ≤ result < 1의 범위를 1 ≤ result < 11의 범위로 변경하는 방법이다.
// 1 <= result < 11
System.out.println((Math.random() * 10) + 1);
Java
복사
•
임의의 정수를 얻는 법
double 형으로 반환되는 랜덤 값을 정수로 받고 싶을 때
// 1 <= result < 11 (정수)
// 1 <= result <= 10 (정수)
System.out.println((int)(Math.random() * 10) + 1);
Java
복사
한 라인에서 두 값 swap하기
자바는 파이썬과 다르게 x, y = y, x 처럼 두 수를 한줄에서 바꾸는 기능이 없다.
물론 임시 변수를 사용할 수 있겠지만, XOR을 사용하여 두 수의 값을 swap 할 수 있다.
int x = 10;
int y = 20;
// (y=x)과정을 통해 y에는 x값이 들어간다. -> 연산이 끝난 후
// (y=x)는 설정된 x값을 반환함
// 식은 x = x ^ y ^ x 형태로 변함 -> x = y가 된다.
x = x ^ y ^ (y=x)
Java
복사
조건문 / 반복문
조건문
파이썬과 다르게, 범위 비교 시 구분하여 작성해야한다.
•
if (90 <= x <= 100) { … } → 사용 불가
•
if (90 <= x && x <= 100) { … } → 사용 가능
문자열 비교 시, equals() 메소드나 equalsIgnoreCase() 메소드를 사용해야 문자열 값으로 비교가 가능하다.
•
str1.equals(str2) : str1와 str2의 문자열 값이 같은지 비교한다. (대소문자 구분)
•
str1.equalsIgnoreCase(str2) : str1와 str2의 문자열 값이 같은지 비교한다. (대소문자 구분 X)
반복문
for문 → for (초기화;조건식;증감식){ … 수행 구문 … } 형식으로 사용된다.
while문 → while(조건식) { … 조건식 결과가 참(true)일 경우 동작될 구문 … } 형식으로 사용된다.
do-while문 → do { … 조건식 결과가 참(true)일 경우 동작될 구문 … } while(조건식); 형식으로 사용된다.
이름을 붙인 반복문 → 반복문에 이름을 붙여 사용한다.
Switch 구문
처리해야 하는 경우의 수가 많을 때 유용한 조건문이다. switch 구문은 아래 2가지 조건을 지키며 사용해야한다.
1.
이때 switch 조건식의 결과는 정수 또는 문자열이어야한다. if 조건문은 boolean 값이 사용된다.
2.
case문의 값은 정수, 상수(문자), 문자열만 가능하며 각 case의 값은 중복되면 안된다.
// 조건식의 결과가 값1 일때, case 값1의 구문 ~ default 구문까지 아래로 동작
// 그래서 case 마다 break를 걸어, 원하는 동작만 실행하고 switch 구문을 빠져나가도록 하는 것이다.
switch(조건식){
case 값1:
// 구문
// ...
break;
case 값2:
// 구문
// ...
break;
default:
// 구문
// ...
break;
}
Java
복사
아래와 같이 여러 케이스가 하나의 구문이 동작하도록 작성도 가능하다.
switch(조건식){
case 값1: case 값2: case 값3:
// 구문
// ...
break;
case 값4: case 값5:
// 구문
// ...
break;
default:
// 구문
// ...
break;
}
Java
복사
구문 마지막에 break; 를 작성하지 않으면, switch 구문을 빠져나가지 않기 때문에 나머지 다음 구문을 실행해버린다.
즉 switch 구문의 case는 구문의 시작점을 고르는 것이라고 할 수 있다.
public class Hello {
public static void main(String[] args) {
int num = 5;
switch(num){
case 1: case 2: case 3:
System.out.println("CASE 1 / CASE 2 / CASE 3");
case 4: case 5:
System.out.println("CASE 4 / CASE 5");
case 6: case 7:
System.out.println("CASE 6 / CASE 7");
default:
System.out.println("default");
}
}
}
// 결과 -> break가 없어 나머지 구문이 전부 실행된 모습
// CASE 4 / CASE 5
// CASE 6 / CASE 7
// default
Java
복사
배열
배열은 같은 타입의 여러 변수를 하나의 묶음으로 다루는 것이다.
한번 선언된 배열의 길이는 그 길이를 바꿀 수 없다.
선언 / 생성
Java에서 배열을 선언하거나 생성하는 방법이다. 동일하게 배열의 인덱스는 0 ~ (배열길이 - 1)까지이다.
여기서 “선언"은 실제 저장공간을 생성하지 않으며, “생성"은 실제 저장공간을 생성한다.
•
배열을 다루기 위한 참조변수를 선언
◦
타입[] 변수이름;
◦
타입 변수이름[];
•
배열을 생성 → 실제 저장공간을 생성한다.
◦
변수이름 = new 타입[길이];
아니면 타입[] 변수이름 = new 타입[길이] 형태로 합쳐서 사용도 가능하다.
또한 초기화를 동시에 진행해주면, 별도로 길이를 설정하지 않아도 된다.
타입[] 변수이름 = { … } 형식으로 사용되며, 자동으로 배열의 길이가 초기화한 값들의 길이로 설정해준다.
단, 이 방법은 이미 선언된 참조변수의 초기 값을 설정하는 경우 new 타입[] 을 제외할 수 없다.
// 자동으로 길이가 5이며, 아래 값들로 초기화된 배열 age가 생성된다.
// 선언 + 생성을 동시에 할 때는, new 타입[] 을 제외할 수 있다.
// 보통은 이 방법을 많이 씀 -> 굳이 별도로 나눠서 하지 않기 때문
int[] age = {10, 20, 30, 40, 50}
// 별도로 선언 후
int[] score;
// new 타입[] 을 제외할 수 없다.
score = new int[]{10, 20, 30, 40, 50}
Java
복사
배열의 기본 값
만약 배열의 길이만 설정할 때는 배열의 타입에 따라 요소들이 기본값으로 설정되는데, 이는 아래와 같다.
참조형 타입 배열(String …)은 기본값이 null이다.
자료형 | 기본값 |
boolean | false |
char | ‘\u0000’ |
byte, short, int | 0 |
long | 0L |
float | 0.0f |
double | 0.0d 또는 0.0 |
참조형 | null |
2차원 배열 선언
2차원 배열은 []를 하나 더 사용하면 된다. 다른 언어와 크게 다른게 없다.
// 기본 선언
int[][] score = new int[10][5]
// 선언 + 초기화
int[][] score = {{10, 20, 30}, {40, 50, 60}}
Java
복사
출력 / 활용
출력
배열을 그냥 출력하게 되면, [I@…. 형태의 문자열이 출력된다. 이는 배열의 주소를 저장한 문자열이다.
하지만 char 타입 배열은 그냥 출력해도 주소 값 대신 요소를 전부 연결한 문자열이 반환된다.
int[] score = {123, 456, 789};
char[] chars = {'a', 'b', 'c', 'd'};
// [I@4617c264
// '[' -> 배열이라는 뜻, 'I' -> int형, '@xxxxxxxx' -> 배열의 주소
System.out.println(score);
// abcd
System.out.println(chars);
Java
복사
그 외의 배열은 모든 요소를 출력하려면 for문을 쓰거나 Arrays.toString() 메서드를 사용한다.
만약 2차원이상 배열일 경우, Arrays.deepToString() 메서드를 사용한다.
int[] score = {123, 456, 789};
// [123, 456, 789]
// "[123, 456, 789]" 라는 문자열이 출력된것이다.
System.out.println(Arrays.toString(score));
int[][] age = {{10, 20, 30}, {40, 50, 60}};
// [[I@4617c264, [I@36baf30c]
// 각 원소가 배열이기 때문에, 주소값을 문자열로 변경하여 출력
System.out.println(Arrays.toString(age));
// [[10, 20, 30], [40, 50, 60]]
// 2차원이상의 배열도 문자열로 잘 출력한다.
System.out.println(Arrays.deepToString(age));
Java
복사
활용
•
배열의 길이를 얻는 법 : 배열이름.length; → int형 상수로 반환
배열을 비교하기
배열을 복사하기
배열을 정렬하기